정보마당



[칼럼] 아이비엠 왓슨과 인공지능의 공개SW
아이비엠 왓슨과 인공지능의 공개SW
저자 : 정휘웅 수석 / 공개SW역량프라자
작성일 : 2017.06.01
과거 하드웨어 성능과 데이터의 부족으로 불가능하다고 생각했던 영역에 인공지능이 속속 반영되고 있으며, 인간의 의사결정을 도와주고 있을 뿐만 아니라 능가하는 사례도 속속 등장하고 있다. 체스처럼 정해진 규칙 기반이 아니어서 인간 수준에는 거의 불가능에 가까울 것이라 예측되었던 바둑 역시 구글 텐서플로(Google TensorFlow) 기술로 수많은 대국 데이터를 기계 학습하여 만들어낸 알파고(Alpha Go)에 따라잡혔다. 또 한 분야에서는 아이비엠 왓슨(IBM Watson)이 병원에서 암 환자의 치료방법에 대한 조언을 담당하는 서비스를 제공하고 있다. 얼핏 보면 두 서비스 모두 인공지능으로 분류될 수 있으나, 두 서비스의 접근 방법은 꽤 다르다.
인공지능에서 소프트웨어만큼 중요한 데이터
인공지능에서 많은 이들이 강조하는 것은 소프트웨어다. 그러나 소프트웨어가 사람의 뇌와 같다면, 그 안을 채우고 있는 지식은 데이터다. 인공지능은 소프트웨어와 지식 데이터 두 가지의 상호 작용에 의해서 구성되는데, 지식 데이터는 학습을 통하여 구축된다. 겉으로 보아서는 다 같은 뇌라 하더라도 각 분야별 전문가마다 알고 있는 단어나 지식이 모두 다른 것과 같은 원리이다.
알파고가 이세돌을 이길 수 있었던 이유 역시 소프트웨어만큼 풍부하게 확보된 대국데이터에 있다. 대국데이터는 순차적으로 나열된 좌표 값의 세트다. 흑과 백을 구분할 이유도 없는 것이, 처음은 무조건 흑의 좌표며 그 이후에는 반복하여 백과 흑이 나타난다. 반복하여 학습시키면 특정 패턴을 찾아내어 적절한 의사결정에 적합한 최적의 값을 제안해줄 수 있다. 그러나 왓슨의 경우 다르다. 학습데이터의 특성이 의학 분야라는 좀 더 전문적인 정보로 구성되어 있다. 엑스레이 혹은 MRI 자료도 있으며, 치료법을 제시하기 위해서는 수많은 의학 정보를 분석하여 기반 정보로 보유하고 있어야 한다.
이렇게 구성된 데이터는 적절한 질의 언어를 통하여 거대한 데이터망에 의해 분석되어야 하는데, 분석된 데이터를 표준화된 구조로 저장하고 있어야만 할 뿐만 아니라, 질의어 역시 기계가 식별 가능한 언어로 변환하여 제공해주어야 한다. 왓슨은 이런 질의/응답 형태에 최적화된 형태로 구성된 인공지능 시스템으로서, 추론(reasoning)이라는 인간의 인지구조(cognitive structure)에 좀 더 가까운 형태를 가지고 있다. 따라서 알파고의 구조와 왓슨의 구조는 상당히 다르다. 따라서 일반적인 질의를 처리하는 데에는 아직까지 적절하지 않으며, 특정 전문분야(의학, 공학 등)에 대한 지식 기반 답변을 내는데 더 적합한 인공지능이라 할 수 있다. 여기에는 전제조건이 필요한데, 해당 전문분야의 풍부한 논문, 기사 정보도 필요하며, MRI나 엑스레이 촬영에 대한 병변 분석 정보(이 때 기계학습 알고리즘이 활용된다)도 함께 필요하다. 이 방대한 데이터들은 기계가 식별 가능한(machine readable) 정보 형태로 저장되어야 하며 이를 통제하는 기반 인프라가 필요하다.
왓슨의 데이터를 만드는 도구, 아파치 UIMA
이러한 인프라를 만들기 위해서는 오랜 시간의 개발과 노력이 필요하기 때문에 공개SW의 도움이 없이는 제대로 시스템을 개발할 수 없다. 이는 왓슨이 특정 분야에 대한 전문적인 지식을 갖고 있는 전문가 시스템이기 때문에, 해당 분야에 대한 정밀 분석이 필요하며, 여기에는 분석 도구가 필요하기 때문이다. 여기에 이용된 공개SW가 아파치 재단의 UIMA(Unstructured Information Management Architecture: 비정형 정보 관리 구조)이며 의학분야에 전문화되어 UIMA 기반으로 구축된 cTAKES라는 의학 자료 전문 용어 분석/관리 도구가 있다. 사실 UIMA는 아이비엠이 처음 개발하기 시작하여 아파치재단으로 공개한 도구라 할 수 있다. 아이비엠이 인공지능 연구를 지속하면서 만들어진 도구가 UIMA이며 이것이 결국 공개SW가 된 셈이다.
UIMA를 짧게 설명하자면 ‘반자동화된 문서 정보 표식 도구(annotation tool)이자 유통/분석 프레임워크’다. 조금 풀어서 쓰자면 HTML에서 ‘title’이나 ‘body’는 해당 부분을 정의하는 태그(tag)라고 한다. 이 태그는 미리 약속되어 있어서 익스플로러, 파이어폭스, 크롬과 같은 여러 브라우저에서 공통적으로 해석된다. 그러나 의학 분야나 심리학 분야 등 특정 학문으로 깊이 들어오는 경우에 우리가 일반적으로 알고 있는 태그를 써서 문서에 표시를 하는 것은 매우 어렵다. 이 때 필요한 것이 문서를 분석하고, 기계가 잘 못 분석한 것을 사람이 수정해주며 유통될 수 있도록 지원하는 도구다. UIMA는 이러한 분석을 지원해주는 공개SW 도구라고 이해하면 된다.
예를 들어 인공지능을 줄여 표현하는 AI라는 약어는 당연히 컴퓨터 분야에서 기술분야 약어이자 전문용어로 분석된다. 그러나 감염병 관련 저널에서는 조류독감의 약어로 분석되어야 한다. 기계가 이 용어의 중의성을 피해서 정보를 분석하기 위해서는 학습되는 문서 정보에 <기술: AI>, <감염병: AI> 형식으로 미리 인간이 중의성을 해소하는 정보를 담아주지 않으면 기계는 통계적으로 문서를 분류하거나 처리하게 되는데, 전문용어가 많이 사용되는 학술분야에서는 약어를 특히 많이 사용하기 때문에 분석을 틀리게 할 확률이 높다.
따라서 기계가 1차적으로 분석하여 태그를 달아준 문서를 토대로 사람이 그 결과를 검수하는 과정이 필요한데, 이 때 지원되는 환경이 UIMA인 것이다. 다음으로는 사람이 질의한 질의어를 분석하고 이를 분절로 나누는 역할도 필요한데 이 역시 UIMA가 수행한다. UIMA는 학습에 필요한 기본적인 정보 흐름을 관리함으로써 인간과 왓슨 사이를 연결해주는 중요한 도구인 셈이다. UIMA가 일반적인 지식을 관리할 수 있는 도구라 한다면 cTAKES는 UIMA에 기반하여 의학분야에 좀 더 특화된 도구라 할 수 있다. 2006년부터 시작되어 UIMA보다 더 일찍 시작되었다. 2012년에 아파치 인큐베이터 프로그램에 선정되었으며, 2013년 정식 아파치 프로젝트가 되었다.
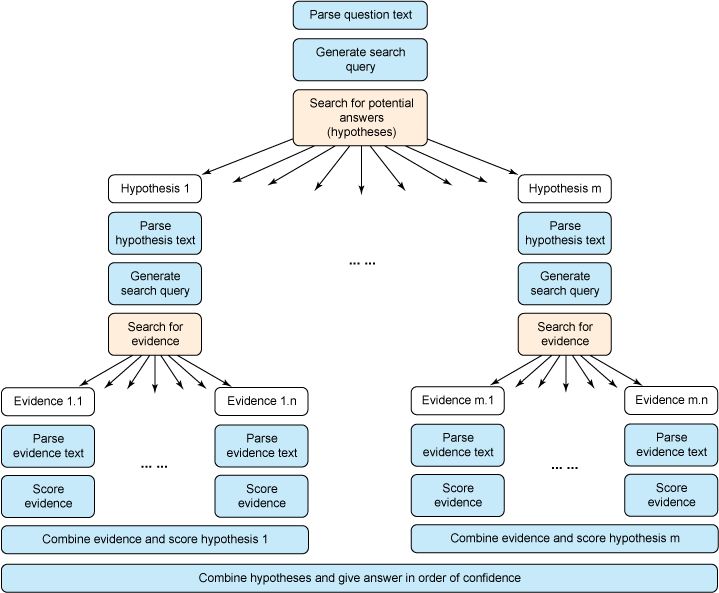
왓슨의 질의어 처리 구조(출처: https://www.ibm.com/developerworks/library/os-ind-watson/)
추론을 지원하는 환경, 루씬(Lucene), 제나(Jena)와 스파큐엘(SPARQL)
루씬은 대부분의 기술자들이 알고 있는 공개SW 부문의 기반 검색엔진이다. 최근 많이 활용되는 일래스틱서치(ElasticSearch)역시 루씬에 기반하고 있다. 루씬의 장점은 대용량 문서의 인덱싱과 검색에 특화되어 있다는 것이다. 잘 정제되어 만들어진 인공지능 데이터라 하더라도 빠르게 인덱싱하고 검색할 수 없으면 무용지물이다. 그렇기 때문에 인공지능시스템에 검색 및 인덱싱을 담당하는 엔진은 필수적이며, 그 역할을 루씬이 담당하고 있다.
검색을 하는 경우에 어떤 용어를 전송하여 어떤 결과값이 반환되어야 하느냐 하는 부분은 다른 문제다. 질의어를 어떻게 구성하며, 제약규칙을 정확하게 정의하여 보내는 것은 검색이나 데이터 정제와는 다른 문제이므로, 이를 구성하고 질의하는 프레임워크가 필요하다. 각 정보들을 추론하는 질의어는 SPARQL(용어와 문서 사이의 관계를 검색하는 언어)이라는 표준 언어로 구성되어 있다. RDF(Resource Description Framework)나 XML 정보에 대한 추론 질의를 보낼 수 있으며, 이 질의와 링크드 데이터(Linked Open Data)를 주고받을 수 있는 인프라를 제공해주는 환경이 아파치 제나다.
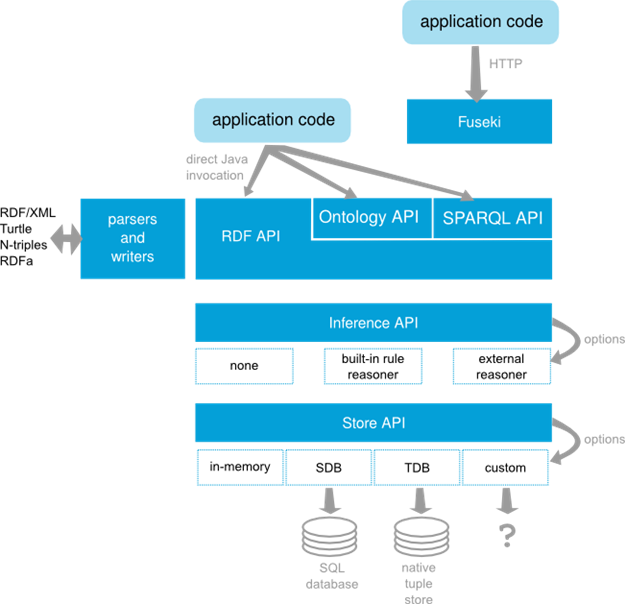
Jena 구조(출처: https://jena.apache.org/getting_started/)
인공지능 시스템을 잘 개발하려면
인공지능을 이야기 하면서 많은 전문가들이 데이터의 중요성을 주장하고 있다. 그러나 어떠한 데이터를 가공할 것이냐 이야기 하면 구체적 방안을 내는 경우는 거의 없다. 인공지능은 학습데이터를 잘 구축하고 이를 검증하는 과정이 반드시 필요하다. 이를 위해서는 정제된 학습데이터 구축이 필요한데, UIMA와 같은 공개SW 프로젝트는 중요한 역할을 담당하고 있다. 다만 UIMA와 같은 도구가 모든 것을 해결할 수 없기 때문에 산업분야 혹은 응용하고자 하는 분야에 맞는 개별적인 라이브러리들이 추가적으로 개발되어야 한다. 2000년대 중반만 하더라도 이러한 도구를 모두 직접 개발하거나 직접 설계해야 했으나, 최근 오픈데이터가 보편화되면서 인공지능을 개발할 수 있는 여건이 많이 개선되었다고 볼 수 있다.
어느 경우든 인공지능은 데이터가 0인 상태에서 만들어질 수 없다. 그리고 데이터를 직접 분석하고 추론 규칙에 반영할 수 있는 정제된 데이터세트를 제공해야 한다. 정제된 학습데이터를 잘 구축하여 추론 규칙을 설계하고, 인공지능 엔진이 추론을 잘 할 수 있도록 만든다면 인공지능 시스템의 기술은 좀 더 빨리 발전할 수 있을 것이다. 물론 그 기저에는 데이터 구축과 함께 추론을 담당하고 고속으로 검색해야 하는 환경에서 공개SW 프로젝트들을 사용하지 않는다면 현재 인공지능 기술 진보 속도를 따라잡을 수 없다는 것은 명심해야 할 것이다.
참고자료
- Brian Sletten, Query RDF data with SPARQL, IBM developerWorks, 2015, https://goo.gl/DkhqEh
- Lars-Erik Bruce, Apache UIMA and Mayo cTAKES, 2012, https://goo.gl/DsTCNx
- Yuan Michael, Watson and healthcare, IBM developerWorks, 2011, https://goo.gl/2sXZkY
- Apache Innovation Bolsters IBM's "Smartest Machine on Earth" in First-ever Man vs. Machine Competition on Jeopardy! Quiz Show, Apache Foundation, 2011, https://goo.gl/PP0Tn9
 공개SW역량프라자 정휘웅 수석에 의해 작성된 ‘아이비엠 왓슨과 인공지능의 공개SW’는 Creative commons 저작자표시-비영리-변경금지 라이선스에 따라 이용할 수 있습니다.
공개SW역량프라자 정휘웅 수석에 의해 작성된 ‘아이비엠 왓슨과 인공지능의 공개SW’는 Creative commons 저작자표시-비영리-변경금지 라이선스에 따라 이용할 수 있습니다. 
0개 댓글