


리뷰 | 스파크용 오픈소스 머신러닝 라이브러리 '스파크 ML'
OSS
게시글 작성 시각 2016-12-05 02:24:57
2016년 11월 30일 (목)
ⓒ CIO, Martin Heller | InfoWorld
지난 3월에도 썼지만 데이터브릭스(Databricks) 서비스는 데이터 과학자를 위한 뛰어난 제품이다. 다양한 수집(ingestion), 특징 선택, 모델 구축, 평가 기능을 갖췄고 데이터 소스와의 통합 기능과 확장성도 장점이다.
데이터브릭스 서비스는 스파크(Spark)의 상위 집합을 클라우드 서비스로 제공한다. 데이터브릭스는 스파크의 첫 개발자인 마테이 자하리아, 그리고 U.C. 버클리의 AMPLab 출신 연구진이 창업한 회사다. 데이터브릭스는 아파치 스파크 프로젝트를 주도하는 기업이기도 하다.
이번 리뷰에서는 스파크용 오픈소스 머신러닝 라이브러리인 스파크 ML에 대해 다룬다. 더 정확히 말하자면 스파크 ML은 스파크용 머신러닝 라이브러리 2개 가운데 더 새로운 라이브러리다.
스파크 1.6부터 대부분의 기능에서 스파크 MLlib 패키지의 RDD 기반 API보다 스파크 ML 패키지의 데이터프레임(DataFrame)기반 API가 우선 권장됐지만 이는 불완전했다. 그러나 스파크 2.0부터 스파크 ML은 완전한 기본 요소가 됐고 스파크 MLlib은 유지보수 모드로 들어갔다.
스파크 ML 기능
스파크 ML 라이브러리는 분류, 회귀, 클러스터링, 협업 필터링과 같은 일반적인 머신러닝 알고리즘(단, 심층 신경망(Deep Neural Network)은 없음)과 함께 특징 추출, 변형, 차원 감소 및 선택을 위한 도구, ML 파이프라인 구축과 평가, 튜닝을 위한 도구를 제공한다.
또한 스파크 ML에는 알고리즘과 모델 및 파이프라인의 저장/로드, 데이터 처리, 선형 대수학과 통계학 수행을 위한 유틸리티도 포함된다.
스파크 ML은 문서에서 MLlib으로 참조되기도 해서 혼란스럽다. 신경 쓰인다면 이전의 스파크 MLlib 패키지를 그냥 무시하고 필자가 언급했던 내용도 모두 잊어버리면 된다.
스파크 ML은 스칼라(Scala)로 작성됐으며 선형 대수학 패키지인 브리즈(Breeze)를 사용한다. 브리즈는 최적화된 수치 처리를 위해 netlib-java에 의존한다. 만일 사용 중인 플랫폼에 머신에 최적화된 네이티브 netlib-java 바이너리 프록시가 있다면 순수 JVM 구현에 비해 전체 라이브러리 실행 속도가 훨씬 더 빨라진다. 이는 맥의 경우 기본적으로 설치되는 애플의 veclib 프레임워크에 해당된다.
여기서 더 운이 좋다면 CPU만 사용하는 기본 아파치 스파크 대신 GPU를 활용하는 데이터브릭스의 스파크 클러스터 구성을 사용할 수 있다. GPU는 빅데이터를 사용한 복잡한 머신러닝 모델 학습 속도를 경우에 따라 10배까지 향상시켜 줄 수 있다. 단, 데이터의 양이 적은 단순한 머신러닝 모델 학습의 경우 머신에 최적화된 CPU 라이브러리에 비해 속도가 더 느려지기도 한다.
MLlib은 분류와 회귀를 위한 다량의 일반적인 알고리즘과 모델을 구현한다. 따라서 초보자에게는 혼란스럽지만 전문가라면 분석할 데이터에 딱 맞는 모델을 찾을 가능성이 높다.
이렇게 풍부한 모델에 더해, 스파크 ML은 중요한 하이퍼파라미터(hyperparameter) 튜닝, 즉 모델 선택 기능도 추가한다. 이 기능을 통해 분석가는 파라미터 그리드, 에스티메이터(estimator), 이벨류에이터(evaluator)를 설정하고 교차 검증 방법(시간이 많이 소비되지만 정확함) 또는 학습 검증 분할 방법(빠르지만 정확도는 떨어짐)으로 데이터에 가장 잘 맞는 모델을 찾을 수 있다.
스파크 ML에는 스칼라 및 자바를 위한 전체 API가 있고, 파이썬용으로도 거의 전체 API가 있으며 R용 일부 API가 있다. 샘플 수를 보면 대략 그 범위를 짐작할 수 있다. 자바는 54개, 스칼라 ML은 60개, 파이썬 ML은 52개이고 R 예제는 5개뿐이다.
스파크 설치(또는 생략)
스파크 설치에 대해 처음에 걱정한 부분은 여러 종속성과 빌드를 오가는 고달픈 작업이 될지도 모른다는 점이었다. 다행히도 그건 기우였다. 2대의 맥에서 최신 스파크 바이너리를 받아 압축을 푸는 것으로 모든 작업이 끝났다.
자바 1.8.0_05는 설치되어 있었으므로 추가 작업 없이 스칼라 2.11.8도 이미 있었다. 파이썬 2.7과 R 3.3.31 역시 설치된 상태였다. 스파크가 하둡 설치를 인지하지 못했을 때 긴장했지만 "WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable"이라는 메시지만 표시되고 이후 문제 없이 진행됐다. 각종 경우에 대한 대비책이 잘 갖춰져 있는 사전 빌드된 바이너리의 장점이다.
현재 기본 스파크 AMI를 사용해서 아마존 EC2에서 스파크 클러스터를 손쉽게 설정하는 방법이 있다. 이미 스파크를 로컬에 설치했고 EC2 권한이 포함된 아마존 계정이 있다면 약 5분이면 된다.
한 서버군에 스파크와 함께 하둡 클러스터를 설치하는 일은 어느 클러스터 관리자를 사용하느냐에 따라 복잡해질 수 있다. 필자는 서버군이 없어 해 보지 않았다. 자체 IT 설비를 운영하는 사람이 아니라면 이 문제에 직접 대처할 일은 없다.
스파크를 설치하지 않고 사용하고자 할 경우 데이터브릭스에서 실행하면 된다. 무료 데이터브릭스 커뮤니티 클러스터는 6GB RAM과 0.88개의 코어가 포함된 노드 하나를 제공한다.
유료 클러스터의 경우 아마존 r3.2xlarge EC2 인스턴스에 구축된 메모리 최적화 노드(30GB, 4코어), 아마존 c3.4xlarge EC2 인스턴스에 구축된 계산 최적화 노드(15GB, 8코어) 또는 아마존 g2.2xlarge(1GPU)에 구축된 GPU 노드 또는 g2.8xlarge(4GPU) EC2 인스턴스 유형을 이용할 수 있다.
데이터브릭스를 사용할 때 얻는 한 가지 장점은 스파크 1.3부터 현재 버전(이 기사를 쓰는 현재 2.0.1)까지 아무 버전을 사용해 클러스터를 만들 수 있다는 점이다.
이것이 중요한 이유는 일부 오래된 스파크 ML 프로그램(샘플 포함)은 특정 스파크 버전에서만 실행되고 다른 버전에서는 오류를 일으키기 때문이다. 보통 샘플 노트북의 주석에 지원되는 스파크 버전이 명시돼 있다.
스파크 ML 실행
데이터브릭스는 스파크 실행을 위해 기본적으로 주피터(Jupyter) 호환 노트북을 제공하지만 표준 아파치 스파크 배포판은 명령줄에서 실행된다. 스파크 리포지토리에는 리포지토리의 샘플 코드 실행을 위한 ./bin/run-example, 수정된 인터랙티브 스칼라 셸 실행을 위한 ./bin/spark-shell, 인터랙티브 파이썬 셸 실행을 위한 ./bin/pyspark, R 셸 실행을 위한 ./bin/sparkR, 애플리케이션 실행을 위한 일반 ./bin/spark-submit 등 여러 가지 스크립트 코드가 있다. spark-submit 스크립트는 다시 spark-class를 실행하고, 이는 자바 및 스파크 .jar 파일을 찾은 다음 적절한 스크립트를 실행한다.
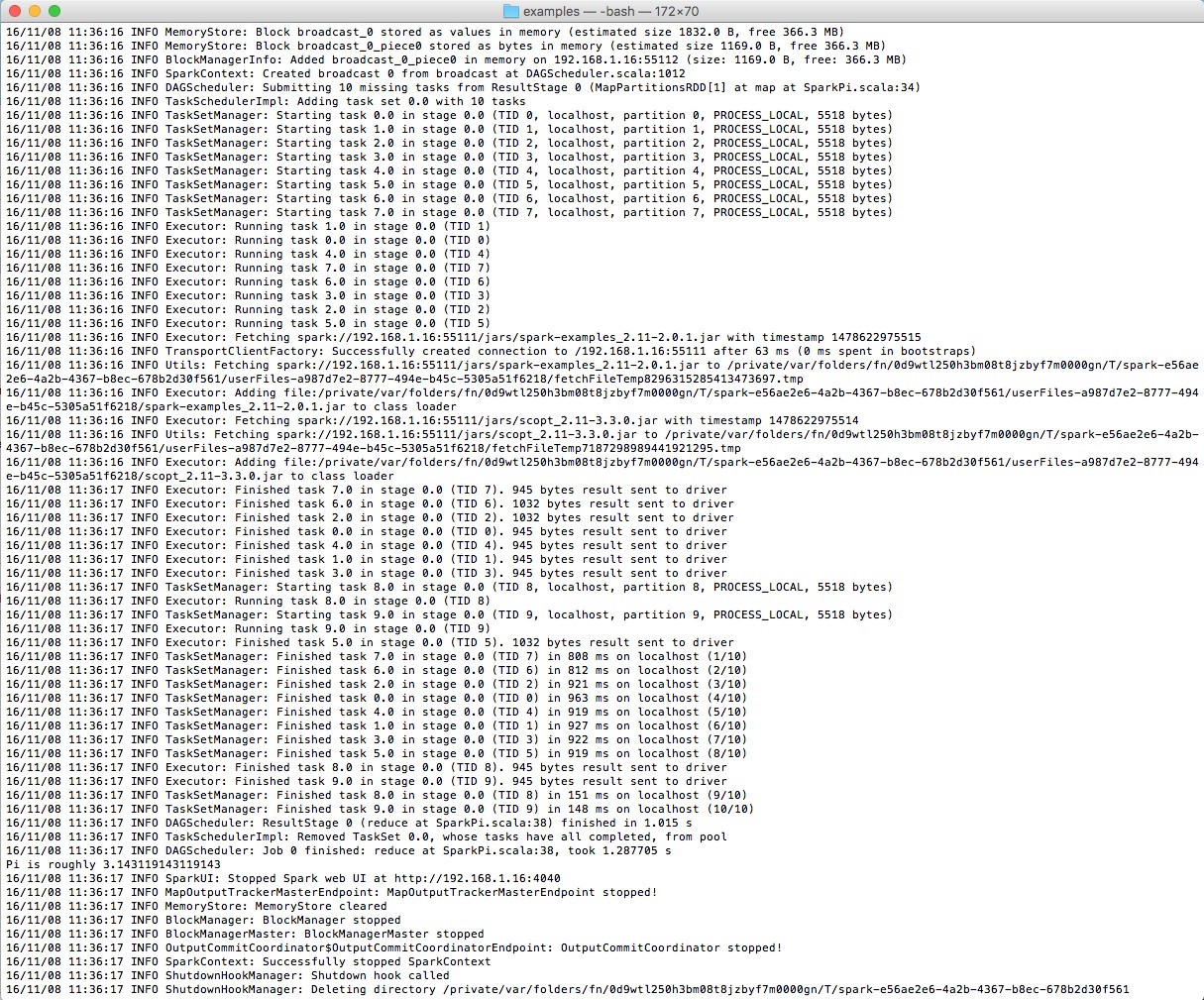
기본적으로 스파크는 실질적인 출력이 거의 없는 경우에도 엄청나게 장황한 로깅 출력을 생성한다. 간단한 스파크 샘플을 실행하면서 캡처한 아래 스크린샷에서 캡션을 읽기 전에 답을 찾을 수 있는지 확인해 보라.
다행히 설정을 통해 터미널 로깅 출력을 줄일 수 있지만 더 나은 스파크 실행 방법이 있다. 주피터 유형 노트북을 사용하면 아래 데이터브릭스 스크린샷과 같이 로깅을 숨기고 설명용 텍스트와 코드, 출력을 사이사이에 배치할 수 있다.
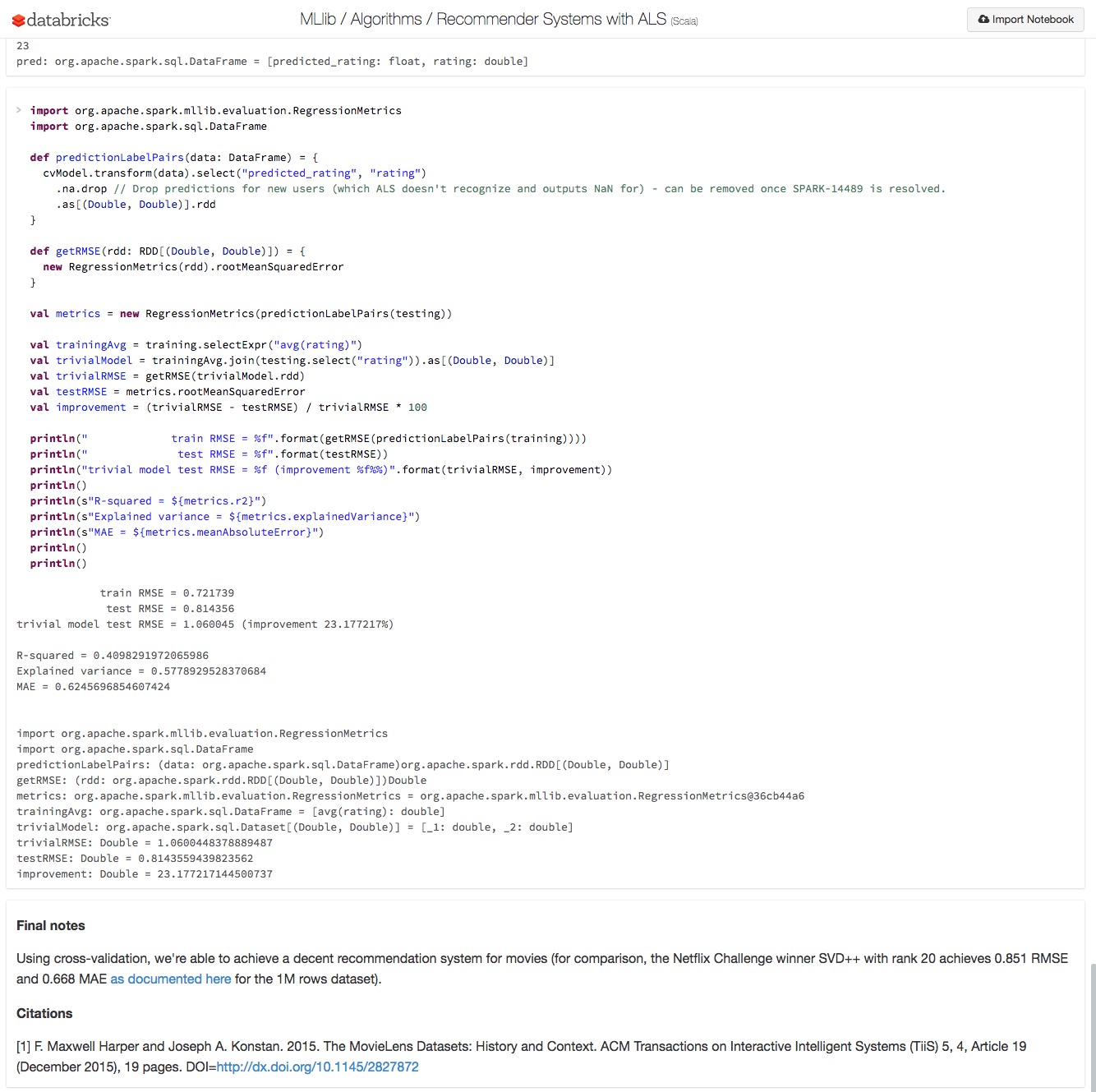
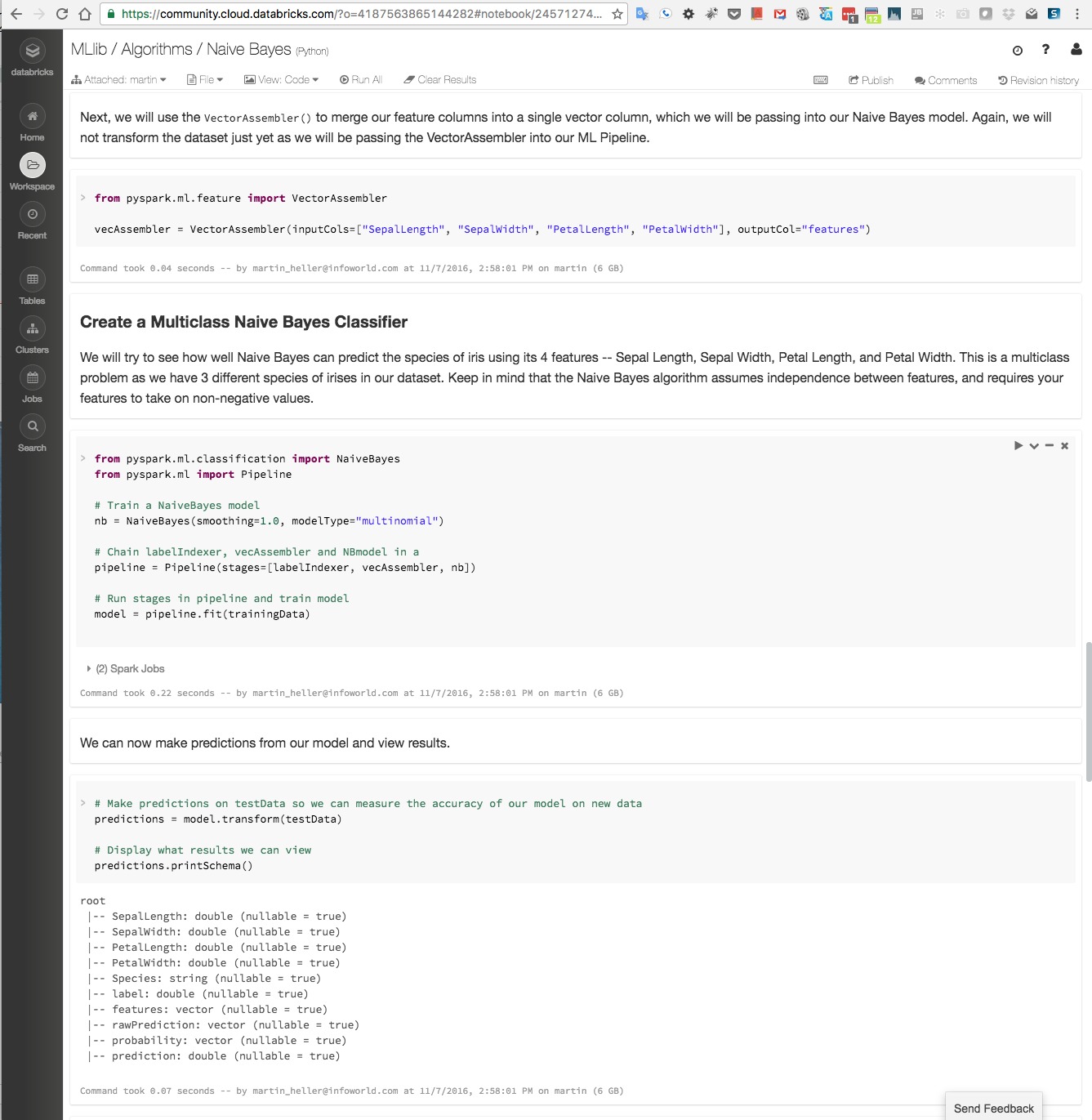
사실 스파크에서 주피터 노트북을 실행하기 위해 데이터브릭스는 필요 없다. 주피터를 로컬에 설치하고 필요한 언어 커널(예를 들어 스칼라, R)을 기본 아이파이썬(IPython) 커널 위에 추가하면 된다.
웹에서 "주피터 노트북과 스파크를 함께 사용하는 방법(how to use Spark with Jupyter notebook)"을 검색하면 매스매티카(Mathematica)와 같은 워크북을 제공하도록 스파크와 주피터를 설정하는 방법에 대한 수십 가지 지침을 찾을 수 있다(한글로는 검색되지 않는다. 편집자 주). 이후 자신의 환경과 가장 근접한 지침을 찾아 선택하면 된다.
스파크 ML 배우기
스파크 사이트에서 다운로드 지침, 배포되는 스칼라, 자바, 파이썬, R 예제 실행 지침, 스파크 API 빠른 시작 및 프로그래밍 가이드, 기타 관련 문서를 찾을 수 있다.
예제 페이지에는 파이썬, 스칼라, 자바로 된 간단한 몇 가지 인스턴스에 대한 설명이 나와 있다. 다운로드한 리포지토리에서 추가 예제를 찾을 수 있다(examples/src/main 디렉터리 트리).
데이터브릭스는 추가 문서와 샘플을 제공한다. 데이터브릭스 환영 페이지에서 시작해서 메인 페이지의 자습서부터 노트북 자습서와 입문 비디오를 살펴볼 수 있다. 클러스터를 추가하고 노트북을 생성하는 방법을 알고 나면 데이터브릭스 문서와 MLlib 문서의 시각화 섹션을 살펴보는 것이 좋다. 위의 노트북 스크린샷 두 개도 여기서 캡처한 것이다. MLlib 알고리즘에 대한 설명에 특히 집중해야 한다.
스파크와 텐서플로우의 만남
지금까지 본 바와 같이 스파크 ML은 특징 선택, 파이프라인, 지속성 등 기본적인 머신러닝에 필요한 요소를 거의 대부분 제공한다. 분류, 회귀, 클러스터링, 필터링 작업에 효과적이다. 스파크의 일부이므로 이용 가능한 데이터베이스, 스트림 및 기타 데이터 소스도 풍부하다.
반면 스파크 ML은 구글 텐서플로우(TensorFlow), 카페(Caffe), 마이크로소프트 코그너티브 툴킷(Cognitive Toolkit)과 같은 방식으로 심층 신경망을 모델링하고 학습시키는 용도로는 적합하지 않다.
이런 이유로 데이터브릭스는 스파크의 확장성과 하이퍼파라미터 튜닝을 텐서플로우의 심층 신경망 학습 및 배치와 결합하기 위한 작업을 추진하고 있다.
하둡이 설치되어 있고 머신러닝을 적용한 데이터 과학을 실행해보고 싶다면 스파크 ML이 가장 좋은 방법이다. 데이터를 적절히 모델링하기 위해 심층 신경망이 필요하다면 스파크 ML은 최선의 선택이 아니다. 그러나 스파크 ML을 다른 최선의 선택 가운데 하나와 결합하면 어느 한 쪽만 사용하는 것보다 더 나은 결과를 얻을 수도 있다.
- 비용: 무료 오픈소스
- 플랫폼: 윈도우와 유닉스 계열 시스템(예: 리눅스, 맥OS)에서 모두 실행되는 스파크, 자바 7 이상, 파이썬 2.6/3.4 이상, R 3.1 이상. 스칼라 API의 경우 스파크 2.0.1은 스칼라 2.11을 사용 editor@itworld.co.kr
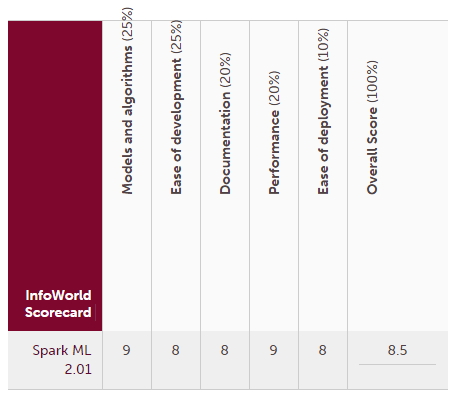
스파크 ML 2.01 인포월드 채점표
데이터브릭스 서비스는 스파크(Spark)의 상위 집합을 클라우드 서비스로 제공한다. 데이터브릭스는 스파크의 첫 개발자인 마테이 자하리아, 그리고 U.C. 버클리의 AMPLab 출신 연구진이 창업한 회사다. 데이터브릭스는 아파치 스파크 프로젝트를 주도하는 기업이기도 하다.
이번 리뷰에서는 스파크용 오픈소스 머신러닝 라이브러리인 스파크 ML에 대해 다룬다. 더 정확히 말하자면 스파크 ML은 스파크용 머신러닝 라이브러리 2개 가운데 더 새로운 라이브러리다.
스파크 1.6부터 대부분의 기능에서 스파크 MLlib 패키지의 RDD 기반 API보다 스파크 ML 패키지의 데이터프레임(DataFrame)기반 API가 우선 권장됐지만 이는 불완전했다. 그러나 스파크 2.0부터 스파크 ML은 완전한 기본 요소가 됐고 스파크 MLlib은 유지보수 모드로 들어갔다.
스파크 ML 기능
스파크 ML 라이브러리는 분류, 회귀, 클러스터링, 협업 필터링과 같은 일반적인 머신러닝 알고리즘(단, 심층 신경망(Deep Neural Network)은 없음)과 함께 특징 추출, 변형, 차원 감소 및 선택을 위한 도구, ML 파이프라인 구축과 평가, 튜닝을 위한 도구를 제공한다.
또한 스파크 ML에는 알고리즘과 모델 및 파이프라인의 저장/로드, 데이터 처리, 선형 대수학과 통계학 수행을 위한 유틸리티도 포함된다.
스파크 ML은 문서에서 MLlib으로 참조되기도 해서 혼란스럽다. 신경 쓰인다면 이전의 스파크 MLlib 패키지를 그냥 무시하고 필자가 언급했던 내용도 모두 잊어버리면 된다.
스파크 ML은 스칼라(Scala)로 작성됐으며 선형 대수학 패키지인 브리즈(Breeze)를 사용한다. 브리즈는 최적화된 수치 처리를 위해 netlib-java에 의존한다. 만일 사용 중인 플랫폼에 머신에 최적화된 네이티브 netlib-java 바이너리 프록시가 있다면 순수 JVM 구현에 비해 전체 라이브러리 실행 속도가 훨씬 더 빨라진다. 이는 맥의 경우 기본적으로 설치되는 애플의 veclib 프레임워크에 해당된다.
여기서 더 운이 좋다면 CPU만 사용하는 기본 아파치 스파크 대신 GPU를 활용하는 데이터브릭스의 스파크 클러스터 구성을 사용할 수 있다. GPU는 빅데이터를 사용한 복잡한 머신러닝 모델 학습 속도를 경우에 따라 10배까지 향상시켜 줄 수 있다. 단, 데이터의 양이 적은 단순한 머신러닝 모델 학습의 경우 머신에 최적화된 CPU 라이브러리에 비해 속도가 더 느려지기도 한다.
MLlib은 분류와 회귀를 위한 다량의 일반적인 알고리즘과 모델을 구현한다. 따라서 초보자에게는 혼란스럽지만 전문가라면 분석할 데이터에 딱 맞는 모델을 찾을 가능성이 높다.
이렇게 풍부한 모델에 더해, 스파크 ML은 중요한 하이퍼파라미터(hyperparameter) 튜닝, 즉 모델 선택 기능도 추가한다. 이 기능을 통해 분석가는 파라미터 그리드, 에스티메이터(estimator), 이벨류에이터(evaluator)를 설정하고 교차 검증 방법(시간이 많이 소비되지만 정확함) 또는 학습 검증 분할 방법(빠르지만 정확도는 떨어짐)으로 데이터에 가장 잘 맞는 모델을 찾을 수 있다.
스파크 ML에는 스칼라 및 자바를 위한 전체 API가 있고, 파이썬용으로도 거의 전체 API가 있으며 R용 일부 API가 있다. 샘플 수를 보면 대략 그 범위를 짐작할 수 있다. 자바는 54개, 스칼라 ML은 60개, 파이썬 ML은 52개이고 R 예제는 5개뿐이다.
스파크 설치(또는 생략)
스파크 설치에 대해 처음에 걱정한 부분은 여러 종속성과 빌드를 오가는 고달픈 작업이 될지도 모른다는 점이었다. 다행히도 그건 기우였다. 2대의 맥에서 최신 스파크 바이너리를 받아 압축을 푸는 것으로 모든 작업이 끝났다.
자바 1.8.0_05는 설치되어 있었으므로 추가 작업 없이 스칼라 2.11.8도 이미 있었다. 파이썬 2.7과 R 3.3.31 역시 설치된 상태였다. 스파크가 하둡 설치를 인지하지 못했을 때 긴장했지만 "WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable"이라는 메시지만 표시되고 이후 문제 없이 진행됐다. 각종 경우에 대한 대비책이 잘 갖춰져 있는 사전 빌드된 바이너리의 장점이다.
현재 기본 스파크 AMI를 사용해서 아마존 EC2에서 스파크 클러스터를 손쉽게 설정하는 방법이 있다. 이미 스파크를 로컬에 설치했고 EC2 권한이 포함된 아마존 계정이 있다면 약 5분이면 된다.
한 서버군에 스파크와 함께 하둡 클러스터를 설치하는 일은 어느 클러스터 관리자를 사용하느냐에 따라 복잡해질 수 있다. 필자는 서버군이 없어 해 보지 않았다. 자체 IT 설비를 운영하는 사람이 아니라면 이 문제에 직접 대처할 일은 없다.
스파크를 설치하지 않고 사용하고자 할 경우 데이터브릭스에서 실행하면 된다. 무료 데이터브릭스 커뮤니티 클러스터는 6GB RAM과 0.88개의 코어가 포함된 노드 하나를 제공한다.
유료 클러스터의 경우 아마존 r3.2xlarge EC2 인스턴스에 구축된 메모리 최적화 노드(30GB, 4코어), 아마존 c3.4xlarge EC2 인스턴스에 구축된 계산 최적화 노드(15GB, 8코어) 또는 아마존 g2.2xlarge(1GPU)에 구축된 GPU 노드 또는 g2.8xlarge(4GPU) EC2 인스턴스 유형을 이용할 수 있다.
데이터브릭스를 사용할 때 얻는 한 가지 장점은 스파크 1.3부터 현재 버전(이 기사를 쓰는 현재 2.0.1)까지 아무 버전을 사용해 클러스터를 만들 수 있다는 점이다.
이것이 중요한 이유는 일부 오래된 스파크 ML 프로그램(샘플 포함)은 특정 스파크 버전에서만 실행되고 다른 버전에서는 오류를 일으키기 때문이다. 보통 샘플 노트북의 주석에 지원되는 스파크 버전이 명시돼 있다.
스파크 ML 실행
데이터브릭스는 스파크 실행을 위해 기본적으로 주피터(Jupyter) 호환 노트북을 제공하지만 표준 아파치 스파크 배포판은 명령줄에서 실행된다. 스파크 리포지토리에는 리포지토리의 샘플 코드 실행을 위한 ./bin/run-example, 수정된 인터랙티브 스칼라 셸 실행을 위한 ./bin/spark-shell, 인터랙티브 파이썬 셸 실행을 위한 ./bin/pyspark, R 셸 실행을 위한 ./bin/sparkR, 애플리케이션 실행을 위한 일반 ./bin/spark-submit 등 여러 가지 스크립트 코드가 있다. spark-submit 스크립트는 다시 spark-class를 실행하고, 이는 자바 및 스파크 .jar 파일을 찾은 다음 적절한 스크립트를 실행한다.
기본적으로 스파크는 실질적인 출력이 거의 없는 경우에도 엄청나게 장황한 로깅 출력을 생성한다. 간단한 스파크 샘플을 실행하면서 캡처한 아래 스크린샷에서 캡션을 읽기 전에 답을 찾을 수 있는지 확인해 보라.
다행히 설정을 통해 터미널 로깅 출력을 줄일 수 있지만 더 나은 스파크 실행 방법이 있다. 주피터 유형 노트북을 사용하면 아래 데이터브릭스 스크린샷과 같이 로깅을 숨기고 설명용 텍스트와 코드, 출력을 사이사이에 배치할 수 있다.
사실 스파크에서 주피터 노트북을 실행하기 위해 데이터브릭스는 필요 없다. 주피터를 로컬에 설치하고 필요한 언어 커널(예를 들어 스칼라, R)을 기본 아이파이썬(IPython) 커널 위에 추가하면 된다.
웹에서 "주피터 노트북과 스파크를 함께 사용하는 방법(how to use Spark with Jupyter notebook)"을 검색하면 매스매티카(Mathematica)와 같은 워크북을 제공하도록 스파크와 주피터를 설정하는 방법에 대한 수십 가지 지침을 찾을 수 있다(한글로는 검색되지 않는다. 편집자 주). 이후 자신의 환경과 가장 근접한 지침을 찾아 선택하면 된다.
스파크 ML 배우기
스파크 사이트에서 다운로드 지침, 배포되는 스칼라, 자바, 파이썬, R 예제 실행 지침, 스파크 API 빠른 시작 및 프로그래밍 가이드, 기타 관련 문서를 찾을 수 있다.
예제 페이지에는 파이썬, 스칼라, 자바로 된 간단한 몇 가지 인스턴스에 대한 설명이 나와 있다. 다운로드한 리포지토리에서 추가 예제를 찾을 수 있다(examples/src/main 디렉터리 트리).
데이터브릭스는 추가 문서와 샘플을 제공한다. 데이터브릭스 환영 페이지에서 시작해서 메인 페이지의 자습서부터 노트북 자습서와 입문 비디오를 살펴볼 수 있다. 클러스터를 추가하고 노트북을 생성하는 방법을 알고 나면 데이터브릭스 문서와 MLlib 문서의 시각화 섹션을 살펴보는 것이 좋다. 위의 노트북 스크린샷 두 개도 여기서 캡처한 것이다. MLlib 알고리즘에 대한 설명에 특히 집중해야 한다.
스파크와 텐서플로우의 만남
지금까지 본 바와 같이 스파크 ML은 특징 선택, 파이프라인, 지속성 등 기본적인 머신러닝에 필요한 요소를 거의 대부분 제공한다. 분류, 회귀, 클러스터링, 필터링 작업에 효과적이다. 스파크의 일부이므로 이용 가능한 데이터베이스, 스트림 및 기타 데이터 소스도 풍부하다.
반면 스파크 ML은 구글 텐서플로우(TensorFlow), 카페(Caffe), 마이크로소프트 코그너티브 툴킷(Cognitive Toolkit)과 같은 방식으로 심층 신경망을 모델링하고 학습시키는 용도로는 적합하지 않다.
이런 이유로 데이터브릭스는 스파크의 확장성과 하이퍼파라미터 튜닝을 텐서플로우의 심층 신경망 학습 및 배치와 결합하기 위한 작업을 추진하고 있다.
하둡이 설치되어 있고 머신러닝을 적용한 데이터 과학을 실행해보고 싶다면 스파크 ML이 가장 좋은 방법이다. 데이터를 적절히 모델링하기 위해 심층 신경망이 필요하다면 스파크 ML은 최선의 선택이 아니다. 그러나 스파크 ML을 다른 최선의 선택 가운데 하나와 결합하면 어느 한 쪽만 사용하는 것보다 더 나은 결과를 얻을 수도 있다.
- 비용: 무료 오픈소스
- 플랫폼: 윈도우와 유닉스 계열 시스템(예: 리눅스, 맥OS)에서 모두 실행되는 스파크, 자바 7 이상, 파이썬 2.6/3.4 이상, R 3.1 이상. 스칼라 API의 경우 스파크 2.0.1은 스칼라 2.11을 사용 editor@itworld.co.kr
스파크 ML 2.01 인포월드 채점표
※ 본 내용은 한국IDG(주)(http://www.itworld.co.kr)의 저작권 동의에 의해 공유되고 있습니다.
Copyright ⓒITWORLD. 무단전재 및 재배포 금지
[원문출처 : www.ciokorea.com/news/32168]

| 번호 | 제목 | 조회수 | 작성 |
|---|---|---|---|
| 공지 | [Open UP 활용가이드] 공개SW 활용 및 개발, 창업, 교육 "Open UP을 활용하세요" | 407667 | 2020-10-27 |
| 공지 | [Open UP 소개] 공개SW 개발·공유·활용 원스톱 지원 Open UP이 함께합니다 | 397488 | 2020-10-27 |
| 5951 | 사건으로 풀어보는 SW·소스코드 기술보호 분쟁 길라잡이 | 3763 | 2016-12-05 |
| 5950 | “우리 회사에 알맞은 클라우드 서비스는?”···아마존, MS, 구글 요금 비교 | 4300 | 2016-12-05 |
| 5949 | 세일피시 OS, 러시아서 안드로이드 대안 떠올라 | 3693 | 2016-12-05 |
| 5948 | 리뷰 | 스파크용 오픈소스 머신러닝 라이브러리 '스파크 ML' | 3954 | 2016-12-05 |
| 5947 | [주간 OSS 동향 리포트] 오픈소스 회사는 어떻게 돈을 버나..수익모델 생각보다 다양 | 4129 | 2016-11-30 |
| 5946 | "IBM, 오픈소스 프로젝트의 최대 스폰서" | 3767 | 2016-11-30 |
| 5945 | 한국MS "오픈소스 시장 19조원 규모…개발 생태계 활성화" | 3629 | 2016-11-30 |
| 5944 | 글로벌 칼럼 | 오픈소스의 승리와 마이크로소프트의 항복 선언 | 4025 | 2016-11-30 |
| 5943 | 내년 국내 SW 산업 주도할 키워드는?…AI·IoT·VR | 3888 | 2016-11-29 |
| 5942 | 30년묵은 윈도-리눅스 기술, 각자 세대교체 | 4016 | 2016-11-29 |
0개 댓글