


'빅데이터·클라우드·오픈소스 집대성' 머신러닝 툴 16선
OSS
게시글 작성 시각 2017-10-10 08:11:17
2017년 9월 28일 (목)
ⓒ CIO Korea, Christina Mercer | Computerworld UK
기업이 영업활동에 인공지능을 적용하는 데 관심이 늘어남에 따라 머신러닝, 즉, 미리 정해진 규칙을 따르는 대신 대규모 데이터 집합으로부터 학습할 수 있는 시스템의 능력은 여러 가지 장점을 제공한다. 예를 들면 금융 서비스에 사기 방지를 위한 예측 모델을 구축한다거나 유통/소매기업이 고객에게 더 나은 추천을 해 줄 수 있게 된다.
구글, 마이크로소프트, IBM, AWS는 모두 각자의 클라우드 플랫폼을 통해 머신러닝 API를 제공한다. 따라서 개발자들이 알고리즘의 복잡성을 추상화하여 서비스를 구축하기가 더 쉬워지고 있다. 또한, 데이터 과학자들이 더욱 깊이 있는 수준에서 사용할 수 있는 오픈소스 딥러닝 프레임워크도 늘어나고 있다.
여기 최신 머신러닝 툴 16가지를 소개한다.









구글, 마이크로소프트, IBM, AWS는 모두 각자의 클라우드 플랫폼을 통해 머신러닝 API를 제공한다. 따라서 개발자들이 알고리즘의 복잡성을 추상화하여 서비스를 구축하기가 더 쉬워지고 있다. 또한, 데이터 과학자들이 더욱 깊이 있는 수준에서 사용할 수 있는 오픈소스 딥러닝 프레임워크도 늘어나고 있다.
여기 최신 머신러닝 툴 16가지를 소개한다.
1. 애저 머신러닝 워크벤치
마이크로소프트는 2017년 9월 ‘이그나이트(Ignite)’ 컨퍼런스 중에 마이크로소프트 애저 머신러닝 툴을 대폭 개선한 내용을 발표했다. 마이크로소프트에서 발표한 3가지 주요 머신러닝 툴 중 하나인 애저 머신러닝 워크벤치는 데이터 및 실험 관리를 위한 교차 플랫폼 클라이언트라고 한다.
이 워크벤치는 파이썬, 스칼라, 파이스파크에서의 모델링을 지원할 것이다.
마이크로소프트는 2017년 9월 ‘이그나이트(Ignite)’ 컨퍼런스 중에 마이크로소프트 애저 머신러닝 툴을 대폭 개선한 내용을 발표했다. 마이크로소프트에서 발표한 3가지 주요 머신러닝 툴 중 하나인 애저 머신러닝 워크벤치는 데이터 및 실험 관리를 위한 교차 플랫폼 클라이언트라고 한다.
이 워크벤치는 파이썬, 스칼라, 파이스파크에서의 모델링을 지원할 것이다.
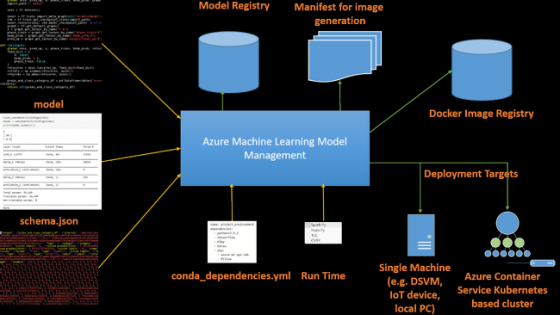
2. 애저 머신러닝 모델 관리
마이크로소프트는 2017년 9월 이그나이트 컨퍼런스에서 애저 머신러닝 모델 관리 툴의 공개도 알렸다.
그 목적은 개발자가 ‘머신러닝 워커플로우와 모델’을 관리하고 배치하는 데 도움을 주는 한편 다음과 같은 모델링 기능을 제공하는 것이다.
- 모델 버전 관리
- 모델 확인
- 모델 생산 배치
- 도커(Docker) 컨테이너를 모델로 생성하고 로컬에서 테스트
- 자동화된 모델 재훈련
- 행동으로 옮길 수 있는 통찰력을 위한 모델 텔레메트리(telemetry) 캡처
마이크로소프트는 2017년 9월 이그나이트 컨퍼런스에서 애저 머신러닝 모델 관리 툴의 공개도 알렸다.
그 목적은 개발자가 ‘머신러닝 워커플로우와 모델’을 관리하고 배치하는 데 도움을 주는 한편 다음과 같은 모델링 기능을 제공하는 것이다.
- 모델 버전 관리
- 모델 확인
- 모델 생산 배치
- 도커(Docker) 컨테이너를 모델로 생성하고 로컬에서 테스트
- 자동화된 모델 재훈련
- 행동으로 옮길 수 있는 통찰력을 위한 모델 텔레메트리(telemetry) 캡처
3. 구글 API
구글은 자체 클라우드 플랫폼에 다수의 머신러닝 툴을 보유하고 있다. 이 중에서 인기 있는 예측(Prediction) API는 사용자가 구글의 알고리즘을 활용해 데이터를 분석하고 미래 결과를 예측할 수 있게 해 준다. 구글은 이 밖에도 스피치(Speech), 번역(Translate), 비전(Vision) 등 사용자가 자신만의 머신러닝 기반 서비스를 구축할 수 있는 API를 추가했다.
2017년 3월, 구글은 동영상 내 개체를 자동으로 인식하여 검색할 수 있게 해 주는 새로운 머신러닝 API를 출범시켰다. 이 API는 클라우드 비디오 인텔리전스(Cloud Video Intelligence)라고 하며 개발자는 이를 이용해 동영상에서 특정 개체를 자동으로 추출할 수 있다. 기본적으로 이 API는 개발자가 검색할 수 있는 단어, 예를 들면 나무 또는 집 같은 단어를 기준으로 동영상 내 이미지에 태그를 붙일 수 있게 해 준다. 현재 개발자들은 베타 버전을 신청할 수 있다.
구글은 자체 클라우드 플랫폼에 다수의 머신러닝 툴을 보유하고 있다. 이 중에서 인기 있는 예측(Prediction) API는 사용자가 구글의 알고리즘을 활용해 데이터를 분석하고 미래 결과를 예측할 수 있게 해 준다. 구글은 이 밖에도 스피치(Speech), 번역(Translate), 비전(Vision) 등 사용자가 자신만의 머신러닝 기반 서비스를 구축할 수 있는 API를 추가했다.
2017년 3월, 구글은 동영상 내 개체를 자동으로 인식하여 검색할 수 있게 해 주는 새로운 머신러닝 API를 출범시켰다. 이 API는 클라우드 비디오 인텔리전스(Cloud Video Intelligence)라고 하며 개발자는 이를 이용해 동영상에서 특정 개체를 자동으로 추출할 수 있다. 기본적으로 이 API는 개발자가 검색할 수 있는 단어, 예를 들면 나무 또는 집 같은 단어를 기준으로 동영상 내 이미지에 태그를 붙일 수 있게 해 준다. 현재 개발자들은 베타 버전을 신청할 수 있다.
4. 아마존의 DSSTNE
‘데스티니’라고 발음하는 DSSTNE(Deep Scalable Sparse Tensor Network Engine)는 데이터 과학자가 GPU를 사용해 심층 신경망을 훈련하고 배치하게 해 주는 오픈소스 딥러닝 라이브러리다. 구글의 텐서플로(TensorFlow) 오픈소스화에 대한 대응이라고 볼 수 있다.
DSSTNE는 거대 온라인 쇼핑 업체인 아마존 웹사이트에서 매일 수억 명의 고객에게 제품을 추천해 주는 추천 엔진을 구동하기 위해 사내 엔지니어들이 구축했다.
아마존은 “DSSTNE를 오픈소스 소프트웨어로 공개하고 있다. 그래야만 딥러닝이 약속하는 것이 말과 언어 이해, 개체 인식을 넘어서 검색 및 추천과 같은 다른 분야로 확장될 수 있기 때문이다. 당사는 전세계의 연구자들이 협업을 통해 이를 개선할 수 있기를 희망한다. 나아가 더 많은 분야에서 혁신의 원동력이 되기를 바란다는 점이 더 중요하다”고 밝혔다.
‘데스티니’라고 발음하는 DSSTNE(Deep Scalable Sparse Tensor Network Engine)는 데이터 과학자가 GPU를 사용해 심층 신경망을 훈련하고 배치하게 해 주는 오픈소스 딥러닝 라이브러리다. 구글의 텐서플로(TensorFlow) 오픈소스화에 대한 대응이라고 볼 수 있다.
DSSTNE는 거대 온라인 쇼핑 업체인 아마존 웹사이트에서 매일 수억 명의 고객에게 제품을 추천해 주는 추천 엔진을 구동하기 위해 사내 엔지니어들이 구축했다.
아마존은 “DSSTNE를 오픈소스 소프트웨어로 공개하고 있다. 그래야만 딥러닝이 약속하는 것이 말과 언어 이해, 개체 인식을 넘어서 검색 및 추천과 같은 다른 분야로 확장될 수 있기 때문이다. 당사는 전세계의 연구자들이 협업을 통해 이를 개선할 수 있기를 희망한다. 나아가 더 많은 분야에서 혁신의 원동력이 되기를 바란다는 점이 더 중요하다”고 밝혔다.
5. 아마존 웹 서비스(AWS) 머신러닝 API
AWS는 2015년 8월 유럽에 아마존 머신러닝 서비스를 출시했다. 그 목적은 보유 기술 수준에 관계없이 모든 개발자가 복잡한 알고리즘에 접근하기 쉽게 만들어주는 것이었다. 이 서비스는 회사 내부 데이터 과학자들이 사용하는 기술을 기반으로 구축되었다.
AWS에 따르면, AWS의 머신러닝 서비스는 레드시프트(RedShift), S3같은 서비스와 관계형 데이터베이스 서비스로부터의 AWS 데이터를 활용하여 하루에 수십억 건의 예측을 생성할 수 있다.
AWS는 2015년 8월 유럽에 아마존 머신러닝 서비스를 출시했다. 그 목적은 보유 기술 수준에 관계없이 모든 개발자가 복잡한 알고리즘에 접근하기 쉽게 만들어주는 것이었다. 이 서비스는 회사 내부 데이터 과학자들이 사용하는 기술을 기반으로 구축되었다.
AWS에 따르면, AWS의 머신러닝 서비스는 레드시프트(RedShift), S3같은 서비스와 관계형 데이터베이스 서비스로부터의 AWS 데이터를 활용하여 하루에 수십억 건의 예측을 생성할 수 있다.
6. 구글 텐서플로
구글도 자체 텐서플로 소프트웨어 라이브러리를 아파치(Apache) 라이선스를 통해 오픈소스화했다. 이를 통해 구글 포토(Google Photos) , 구글 클라우드 스피치(Google Cloud Speech) 를 비롯한 많은 자체 서비스가 구동되고 있으며, 이제는 구글 딥마인드(DeepMind) 부서에서 연구용으로 사용되고 있다.
텐서플로우는 CPU 또는 GPU에서 처리 가능한 C++ 또는 파이썬 그래프를 생산할 수 있다. 이 흐름 그래프는 시스템을 관통하는 데이터의 움직임을 묘사한다.
구글도 자체 텐서플로 소프트웨어 라이브러리를 아파치(Apache) 라이선스를 통해 오픈소스화했다. 이를 통해 구글 포토(Google Photos) , 구글 클라우드 스피치(Google Cloud Speech) 를 비롯한 많은 자체 서비스가 구동되고 있으며, 이제는 구글 딥마인드(DeepMind) 부서에서 연구용으로 사용되고 있다.
텐서플로우는 CPU 또는 GPU에서 처리 가능한 C++ 또는 파이썬 그래프를 생산할 수 있다. 이 흐름 그래프는 시스템을 관통하는 데이터의 움직임을 묘사한다.
7. 마이크로소프트 DMLT
마이크로소프트의 머신러닝 툴킷(깃허브(Github) 에서 사용 가능)의 목적은 혼잡한 머신러닝 클러스터의 불편을 덜어줌으로써 여러 개의 (그리고 서로 다른) 머신러닝 애플리케이션을 동시에 실행하기 더 쉽게 만들어 주는 것이다.
마이크로소프트 측은 “대형 모델일수록 다양한 애플리케이션에서 정확성이 높아지는 경향이 있다”고 전제하며 “일반 머신러닝 연구자와 수행자가 대형 모델을 배우기에는 여전히 어렵다”고 덧붙였다.
마이크로소프트의 머신러닝 툴킷(깃허브(Github) 에서 사용 가능)의 목적은 혼잡한 머신러닝 클러스터의 불편을 덜어줌으로써 여러 개의 (그리고 서로 다른) 머신러닝 애플리케이션을 동시에 실행하기 더 쉽게 만들어 주는 것이다.
마이크로소프트 측은 “대형 모델일수록 다양한 애플리케이션에서 정확성이 높아지는 경향이 있다”고 전제하며 “일반 머신러닝 연구자와 수행자가 대형 모델을 배우기에는 여전히 어렵다”고 덧붙였다.
8. 마이크로소프트 CNTK
역시 마이크로소프트의 CNTK(Computational Network Toolkit) 는 사용자가 방향 그래프에 표시된 신경망을 생성하게 해 준다. 주로 음성 인식 기술을 위해 만들어졌지만 2015년 4월 이후에는 이미지, 텍스트, RNN(Recurrent Neural Network: 일종의 신경망) 훈련을 지원하는 보다 일반적인 머신러닝 툴킷으로 자리 잡았다.
역시 마이크로소프트의 CNTK(Computational Network Toolkit) 는 사용자가 방향 그래프에 표시된 신경망을 생성하게 해 준다. 주로 음성 인식 기술을 위해 만들어졌지만 2015년 4월 이후에는 이미지, 텍스트, RNN(Recurrent Neural Network: 일종의 신경망) 훈련을 지원하는 보다 일반적인 머신러닝 툴킷으로 자리 잡았다.
9. IBM 왓슨 애널리틱스
왓슨 애널리틱스(Watson Analytics) 클라우드 서비스는 2014년 왓슨을 게임 쇼 우승자에서 진정한 기업용 소프트웨어로 탈바꿈하려는 IBM 계획의 일환으로 공개됐다.
왓슨 애널리틱스의 목적은 예측 분석에 경험이 전무한 조직들이 업무 데이터를 제대로 사용할 수 있도록 도움을 주는 것이다.
IBM은 이미 2013년에 왓슨 개발자 클라우드를 출범시킨 바 있다. 서비스 클라우드로서의 블루믹스(Bluemix) 플랫폼을 통해 API에 접근하게 해 줌으로써 개발자들이 왓슨의 지능을 바탕으로 애플리케이션을 만들 수 있게 해 주었다.
왓슨 애널리틱스(Watson Analytics) 클라우드 서비스는 2014년 왓슨을 게임 쇼 우승자에서 진정한 기업용 소프트웨어로 탈바꿈하려는 IBM 계획의 일환으로 공개됐다.
왓슨 애널리틱스의 목적은 예측 분석에 경험이 전무한 조직들이 업무 데이터를 제대로 사용할 수 있도록 도움을 주는 것이다.
IBM은 이미 2013년에 왓슨 개발자 클라우드를 출범시킨 바 있다. 서비스 클라우드로서의 블루믹스(Bluemix) 플랫폼을 통해 API에 접근하게 해 줌으로써 개발자들이 왓슨의 지능을 바탕으로 애플리케이션을 만들 수 있게 해 주었다.
10. 빅ML
클라우드에서 인공지능으로 이동하는 것은 대형 IT 회사만이 아니다. 빅ML(BigML) 은 인공지능을 더 폭넓은 대상에게 공개하는 것을 목적으로 하는 시장 내 여러 신생기업 가운데 하나다.
2011년 미국 오레곤 주에 설립된 빅ML은 사용자가 데이터 집합을 업로드해 예측을 시작할 수 있는 단순한 사용자 인터페이스를 제공한다.
원문보기:
http://www.ciokorea.com/slideshow/35760#csidx7b6239a6257e988b86d2d7c6b70e404
클라우드에서 인공지능으로 이동하는 것은 대형 IT 회사만이 아니다. 빅ML(BigML) 은 인공지능을 더 폭넓은 대상에게 공개하는 것을 목적으로 하는 시장 내 여러 신생기업 가운데 하나다.
2011년 미국 오레곤 주에 설립된 빅ML은 사용자가 데이터 집합을 업로드해 예측을 시작할 수 있는 단순한 사용자 인터페이스를 제공한다.
원문보기:
http://www.ciokorea.com/slideshow/35760#csidx7b6239a6257e988b86d2d7c6b70e404
11. 아파치 스파크 MLlib 및 싱가
아파치 스파크(Spark) MLlib는 인메모리 데이터 처리 프레임워크다. 스파크는 (인메모리 데이터 처리를 위한) 분류, 회귀, 클러스터링, 협업 필터링 등이 포함된 유용한 알고리즘과 유틸리티의 라이브러리를 제공한다. 이 대규모 라이브러리는 계속 커지고 있다.
싱가(Singa) 는 아파치 인큐베이터 내의 오픈소스 프레임워크로서 여러 시스템에 걸친 딥러닝 네트워크를 위한 프로그래밍 도구를 제공한다.
아파치 스파크(Spark) MLlib는 인메모리 데이터 처리 프레임워크다. 스파크는 (인메모리 데이터 처리를 위한) 분류, 회귀, 클러스터링, 협업 필터링 등이 포함된 유용한 알고리즘과 유틸리티의 라이브러리를 제공한다. 이 대규모 라이브러리는 계속 커지고 있다.
싱가(Singa) 는 아파치 인큐베이터 내의 오픈소스 프레임워크로서 여러 시스템에 걸친 딥러닝 네트워크를 위한 프로그래밍 도구를 제공한다.
12. 벨레스
벨레스(Veles)는 삼성의 분산형 딥러닝 플랫폼이다. C++로 작성되었으며 노드 간 조정에 파이썬을 이용한다. 벨레스는 훈련받은 모델을 즉시 사용할 수 있게 해 주는 API를 제공하며 데이터 분석에 사용될 수 있다.
벨레스(Veles)는 삼성의 분산형 딥러닝 플랫폼이다. C++로 작성되었으며 노드 간 조정에 파이썬을 이용한다. 벨레스는 훈련받은 모델을 즉시 사용할 수 있게 해 주는 API를 제공하며 데이터 분석에 사용될 수 있다.
13. 알리바바의 알리윤
2015년 8월, 중국 전자상거래 업계의 거물 알리바바는 자체 클라우드 컴퓨팅 사업인 알리윤(Aliyun)이 기업 고객의 분석 소프트웨어 개발 간소화에 도움이 될 머신러닝 서비스를 제공할 것이라고 발표했다.
이 기술의 기반이 되는 알리윤의 오픈 데이터 처리 서비스(ODPS) 기술은 6시간 이내에 100 페타바이트의 데이터를 처리할 수 있다.
DT PAI 플랫폼은 개발 과정을 단순화할 수 있는 끌어 놓기 방식의 인터페이스를 제공한다.
서비스 발표 당시 알리바바 클라우드 사업의 수석 제품 전문가 샤오 웨이는 “며칠이 걸리던 것을 몇 분 이내에 마칠 수 있다”고 밝혔다.
2015년 8월, 중국 전자상거래 업계의 거물 알리바바는 자체 클라우드 컴퓨팅 사업인 알리윤(Aliyun)이 기업 고객의 분석 소프트웨어 개발 간소화에 도움이 될 머신러닝 서비스를 제공할 것이라고 발표했다.
이 기술의 기반이 되는 알리윤의 오픈 데이터 처리 서비스(ODPS) 기술은 6시간 이내에 100 페타바이트의 데이터를 처리할 수 있다.
DT PAI 플랫폼은 개발 과정을 단순화할 수 있는 끌어 놓기 방식의 인터페이스를 제공한다.
서비스 발표 당시 알리바바 클라우드 사업의 수석 제품 전문가 샤오 웨이는 “며칠이 걸리던 것을 몇 분 이내에 마칠 수 있다”고 밝혔다.
14. 카페
카페(Caffe) 는 딥러닝 C++ 프레임워크로서 애초에 머신 비전 목적(이미징 기반의 자동 검사)으로 만들어진 것이다. 버클리 비전 및 학습 센터(BVLC) 와 커뮤니티 개발자들에 의해 개발됐다.
이 프레임워크는 이미 “학술 연구 프로젝트, 신생업체 원형, 심지어 시각, 언어, 멀티미디어 분야에서 대규모 산업 애플리케이션”의 일부로 사용되고 있다.
야후는 최근 카페온스파크(CaffeOnSpark)를 오픈소스화하면서 딥러닝 기능과 스파크 데이터 처리 엔진을 결합했다.
구글과 핀터레스트 역시 카페를 영업활동에 활용해 왔다.
카페(Caffe) 는 딥러닝 C++ 프레임워크로서 애초에 머신 비전 목적(이미징 기반의 자동 검사)으로 만들어진 것이다. 버클리 비전 및 학습 센터(BVLC) 와 커뮤니티 개발자들에 의해 개발됐다.
이 프레임워크는 이미 “학술 연구 프로젝트, 신생업체 원형, 심지어 시각, 언어, 멀티미디어 분야에서 대규모 산업 애플리케이션”의 일부로 사용되고 있다.
야후는 최근 카페온스파크(CaffeOnSpark)를 오픈소스화하면서 딥러닝 기능과 스파크 데이터 처리 엔진을 결합했다.
구글과 핀터레스트 역시 카페를 영업활동에 활용해 왔다.
15. 네온
네온(Neon)은 네르바나(Nervana)의 오픈소스, 파이썬 기반의 머신러닝 라이브러리다.
2014년 설립된 딥러닝 신생업체인 네르바나는 네온을 기반으로 한 클라우드 서비스도 출범했다. 네르바나 측의 주장에 따르면, 경쟁 서비스보다 속도가 10배 빠르다고 한다. 기업들의 딥러닝 기술 구축, 훈련, 배치가 훨씬 더 빨라진다는 것을 의미한다.
네온(Neon)은 네르바나(Nervana)의 오픈소스, 파이썬 기반의 머신러닝 라이브러리다.
2014년 설립된 딥러닝 신생업체인 네르바나는 네온을 기반으로 한 클라우드 서비스도 출범했다. 네르바나 측의 주장에 따르면, 경쟁 서비스보다 속도가 10배 빠르다고 한다. 기업들의 딥러닝 기술 구축, 훈련, 배치가 훨씬 더 빨라진다는 것을 의미한다.
16. Wise.io
Wise.io의 목표도 이미 기업에서 사용할 준비가 된 ‘서비스로서의 머신러닝’으로 인공지능의 사용을 대중화하는 것이다. 2012년 미국 캘리포니아 주에서 설립된 이 신생업체의 알고리즘은 애초에 천문학자들의 새로운 항성 발견과 지도 작성에 도움을 줄 목적으로 개발되었다가 나중에 기업들이 활용하게 되었다.
고객사로는 폭스바겐, 시트릭스 등이 있다.
Wise.io의 목표도 이미 기업에서 사용할 준비가 된 ‘서비스로서의 머신러닝’으로 인공지능의 사용을 대중화하는 것이다. 2012년 미국 캘리포니아 주에서 설립된 이 신생업체의 알고리즘은 애초에 천문학자들의 새로운 항성 발견과 지도 작성에 도움을 줄 목적으로 개발되었다가 나중에 기업들이 활용하게 되었다.
고객사로는 폭스바겐, 시트릭스 등이 있다.
※ 본 내용은 한국IDG(주)(http://www.itworld.co.kr)의 저작권 동의에 의해 공유되고 있습니다.
Copyright ⓒITWORLD. 무단전재 및 재배포 금지

| 번호 | 제목 | 조회수 | 작성 |
|---|---|---|---|
| 공지 | [Open UP 활용가이드] 공개SW 활용 및 개발, 창업, 교육 "Open UP을 활용하세요" | 407607 | 2020-10-27 |
| 공지 | [Open UP 소개] 공개SW 개발·공유·활용 원스톱 지원 Open UP이 함께합니다 | 397434 | 2020-10-27 |
| 7381 | 무료 대안 오피스 라운드업 : MS 오피스 온라인 "간편한 협업용 도구" | 5204 | 2017-10-10 |
| 7380 | 무료 대안 오피스 라운드업 : MS 오피스의 ‘원조’ 대안 아파치 오픈 오피스 | 5512 | 2017-10-10 |
| 7379 | 무료 대안 오피스 라운드업 : 오픈소스 오피스 대안 리브레 오피스 5 | 5667 | 2017-10-10 |
| 7378 | 무료 대안 오피스 라운드업 : 협업이 필요할 때? 답은 구글 문서 | 5309 | 2017-10-10 |
| 7377 | 무료 대안 오피스 라운드업 : 최신 오피스 파일 형식 지원이 아쉬운 프리오피스 2016 | 5501 | 2017-10-10 |
| 7376 | '빅데이터·클라우드·오픈소스 집대성' 머신러닝 툴 16선 | 5937 | 2017-10-10 |
| 7375 | 애플, 주요 운영체제 '밑단' 오픈소스로 공개 | 4932 | 2017-10-10 |
| 7374 | MS 블록체인 비즈니스가 주목되는 이유 | 5752 | 2017-10-10 |
| 7373 | '리액트 보이콧' 사태에 백기든 페이스북 | 5273 | 2017-10-10 |
| 7372 | "4차 산업혁명, 금융산업에서 활성화 뚜렷"...삼정KPMG 보고서 | 4612 | 2017-10-10 |
0개 댓글