정보마당



[2월 월간 브리핑] 한국어 자연어 처리(NLP) 오픈소스 프로젝트
-
자연어 처리 기술은 AI와 함께 수요가 증가하고 있으며 가장 주목받고 있는 기술임
-
활성화된 자연어 처리 오픈소스들은 타 분야까지 영향을 끼쳐 산업 전반의 혁신을 가져오고 있음
-
-
한국어 자연어 처리 오픈소스 프로젝트들로 khaiii, KoGPT-2, KoBERT, Kiwi 등이 있음
-
각 프로젝트는 고유한 기능과 강점을 가지고 한국어 자연어 처리 오픈소스 생태계를 이끌고 있음
-
□ 자연어 처리(NLP) 오픈소스 프로젝트는 급성장하는 NLP 시장에서 최첨단 기술, 도구 및 사전훈련된 모델에 대한 액세스를 제공하고 진입 장벽을 낮춰주어 NLP 분야의 발전을 더욱 활성화함
◎ NLP 시장은 연간 25.7%의 고속 성장으로 2027년까지 시장이 3배가량 확대될 예정이며, NLP 오픈소스 프로젝트들이 NLP 시장 성장 견인에 큰 역할을 할 전망임

자연어 처리(NLP) 시장 개관
출처: https://www.marketsandmarkets.com
- 자연어 처리에 대한 수요가 다양한 분야에서 적용 및 확산이 되고 있음. 애플리케이션 부문은 고객 경험 관리, 가상 비서, 소셜 미디어 모니터, 감정 분석, 텍스트 분류 및 요약 등으로 분야를 세분화해 분석을 진행했으며, 채용 분야에 자연어 처리 기술을 적용해 의미 있는 상호 작용 시간을 확보할 수 있을 것으로 진단함. 여기에 클라우드 컴퓨팅 기반으로 업무 프로세스가 전환되고, 클라우드 기반의 자연어 처리 솔루션이 빠르게 보급되면서 시장 조성과 성장의 발판이 되고 있음. 특히, 사용자의 의도 파악이 필요한 분야에서 자연어 처리 기술이 주목을 받고 있음.
- 고객 경험 관리, 가상 비서, 소셜 미디어 모니터, 감정 분석, 텍스트 분류 및 요약 등 세분화된 분야에 자연어 처리 기술을 적용하여 경제적으로 의미 있는 결과를 낼 것으로 보임. 오늘날 의료 기록부터 소셜 미디어에 이르기까지 엄청난 양의 텍스트 및 음성 데이터를 효율적이고 일관적이며 중립적인 방식으로 분석하기 위해서는 자동화가 필수적임.
◎ 자연어 처리(NLP)에 대한 수요가 급증하는 상황에서 NLP 오픈소스 프로젝트의 역할
- 해당 분야에 처음 접하는 연구자 및 개발자의 진입 장벽을 낮춰줌. 오픈소스 프로젝트는 일반적으로 자유롭게 이용할 수 있고 문서화가 잘 갖춰져 있으므로 NLP 연구 개발에 유용한 자원이 될 수 있음.
- 모듈화를 통한 용이한 결합성 제공. 특정 기능을 가진 부분만을 따로 떼어낼 수 있는 모듈화를 통해서 특정 구성 요소를 다른 시스템과 쉽게 결합할 수 있고, 이를 통해 다양한 프로젝트와 도구들을 결합하여 복잡한 NLP 시스템을 쉽게 구축할 수 있음.
- 또한, 무엇보다 오픈소스는 누구나 이용이 가능하며 기술을 발전시킬 수 있으므로 이를 활용한 기술 개발을 통해 급성장하는 산업에서 우위를 점할 수 있도록 함. 대표적인 결과물의 예로 ChatGPT를 들 수 있음.
◎ 2022년 IT업계의 최고의 화두인 ChatGPT는 현시점에서 NLP 모델의 정점에 달한 기술로 평가받으며 IT업계를 넘어서 예술, 법률과 같은 다른 영역에까지 영향력을 끼치고 있음.
- ChatGPT는 OpenAI가 개발한 자연어 처리(NLP) 모델로, 인공지능을 이용해 인간의 언어를 이해하고 생성할 수 있음. ChatGPT를 통해 언어 번역, 텍스트 생성, 질의응답 등의 특정 작업이 가능함.
- 자연어 처리 모델을 기반으로 질문을 이해하고 답변을 하며, 에세이나 기사, 소설을 창작하기도 함. 이는 자연어 처리 모델과 딥러닝 모델이 결합하였기에 가능한 결과물로, 공개됨과 동시에 전 세계를 놀라게 함.

챗GPT(ChatGPT)에 윤동주의 '서시'의 의미를 분석하라고 입력한 결과
출처: https://www.news1.kr
- ChatGPT 개발을 위해 마이크로소프트사는 OpenAI에 100억 달러(약 12조 3500억 원)에 이르는 투자를 한 것으로 알려져 있으며, 딥러닝과 결합된 자연어 처리 오픈소스 프로젝트의 대표적인 성공 사례를 넘어 세계적인 산업 전반을 바꿀 핵심 요소가 될 것으로 전망됨.
□ 한국어 자연어 처리 오픈소스 프로젝트들은 고유한 기능과 강점으로 자연어 처리 분야의 발전에 기여하고 있음.
- 시장과 NLP 응용 솔루션에 기반이 되는 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료 ‘말뭉치(말모둠, 글모둠)’는 양이 많을수록 AI가 인식(이해)할 수 있는 자연어의 정확도가 높아지며, AI가 얼마나 많이 학습하느냐에 따라 그 성능을 좌우함.
- 국내에서는 지난 1998년부터 정부가 ‘21세기 세종계획’을 통해 ‘세종 말뭉치’를 구축해왔으나, 2007년 이후로 사업이 중단됨. 이후, 자연어 처리 등 AI의 핵심기술 개발을 위한 국어 자료 구축이 필요하다고 판단한 정부는 2017년을 시작으로 2019년 국립국어원 예산 중 말뭉치 구축만을 위한 예산 204억 원을 별도로 책정해 10억 어절을 말뭉치로 구축하는 사업을 진행했으며, 2022년까지 150억 어절 규모의 말뭉치 구축을 목표로 세움.
- 한국어 NLP 오픈소스 프로젝트들은 형태학적 분석, 음성 부분 태그 지정, 개체명 인식과 같은 다양한 NLP 도구를 제공하는 것이 주요 특징임. 형태학적 분석 또는 형태소 분석이라고 불리는 기술은 2개 이상의 글자로 이루어진 단어 혹은 문장 입력 시, 의미를 가진 언어 단위 중 가장 작은 단위인 형태소 단위로 자동으로 분리하는 기술임.
- 예를 들어, ‘학교에 간다’라고 입력하면 ’학교/명사+ 에/조사+ 가/동사+ ㄴ다/어미’로 형태소 단위와 품사를 파악해 분류해냄. 한국어 NLP 오픈소스 프로젝트별로 이러한 형태소 분석을 하는 방법에 대한 차이가 존재하고 그에 따라 고유한 기능과 특징이 있다고 볼 수 있음. 주요 한국어 자연어 처리 오픈소스 프로젝트에는 khaiii, Kiwi, KOMORAN, KoBERT, KoGPT-2가 있으며, 이에 대해 소개함.
◎ khaiii
- Kakao Hangul Analyzer Ⅲ의 약자이며, 국내기업 카카오가 딥러닝 기술 기반으로 개발하였음. 세종 코퍼스를 이용하여 CNN(Convolutional Neural Network, 합성곱 신경망) 기술을 적용해 학습한 형태소 분석기임. 이는 주로 자연어처리 응용 서비스의 기반 기술로 사용되며 정보 검색, 기계 번역, 스마트스피커나 챗봇 등 여러 서비스에서 사용할 수 있음
- 딥러닝 기술을 이용해 음절 기반으로 형태소를 분석하는 방법을 채택함. 기존의 분석기(dha1, dha2)는 규칙 기반으로 동작하므로 지속적으로 규칙을 입력해줘야 하지만, khaiii는 데이터 기반으로 동작하므로 기계학습 알고리즘(딥러닝)을 사용함.
- Decoder를 C++로 구현하여 GPU 없이도 비교적 빠르게 동작하며, Python 바인딩을 제공하고 있어서 편리하게 사용할 수 있음. 카카오는 국립국어원에서 배포한 데이터인 세종 코퍼스를 기반으로 데이터의 오류를 수정, 자체 구축한 데이터를 추가해 약 85만 문장, 1300만 어절의 데이터를 학습해 정확도를 높임
* 바인딩 : 변수가 실제 데이터가 존재하는 위치를 가리키고 있는 것
- - 기계학습에 사용한 알고리즘은 신경망 알고리즘 중에서 Convolutional Neural Network(CNN)를 사용함. 한국어에서 형태소 분석은 자연어처리를 위한 가장 기본적인 전처리 과정이므로 속도가 매우 중요한 요소임. 따라서 자연어 처리에 많이 사용하는 Long-Short Term Memory(LSTM)와 같은 Recurrent Neural Network(RNN) 알고리즘은 속도 면에서 활용도가 떨어질 것으로 예상하여 고려 대상에서 제외함.
- 신경망 알고리즘은 소위 말하는 블랙박스 알고리즘으로 결과를 유추하는 과정을 사람이 따라가기가 쉽지 않음. 따라서 오분석이 발생할 경우, 모델의 파라미터를 수정하여 바른 결과를 내도록 하는 것이 매우 어려움. 따라서 이를 위해 khaiii에서는 신경망 알고리즘의 앞단에 기분석 사전과 뒷단에 오분석 패치라는 두 가지 사용자 사전 장치를 마련함.

khaiii로 형태소를 분석한 결과(IOB1 방식)
출처 : https://tech.kakao.com/2018/12/13/khaiii/
◎ Kiwi
- 토큰화, 음성 부분 태깅, 개체명 인식과 같은 다양한 NLP 작업을 위한 간단하고 사용하기 쉬운 인터페이스를 제공하는 것을 목표로 하며 Hugging Face 오픈소스 프로젝트를 기반으로 함. C++ 프로그래밍 언어로 구현된 프로젝트를 기반으로, 다른 패키지에 의존성이 없으며 다양한 프로그래밍 언어에 사용할 수 있도록 준비 중임.
* Hugging Face: 자연어 처리를 다루는 미국의 스타트업
- 형태소 분석은 세종 품사 태그 체계를 기반으로 하고 있으며 모델 학습에는 세종계획 말뭉치와 모두의 말뭉치를 사용하고 있음. 웹 텍스트의 경우 약 87%, 문어 텍스트의 경우 약 94% 정도의 정확도로 한국어 문장의 형태소를 분석해 낼 수 있으며, 또한 간단한 오타의 경우 모델 스스로 교정하는 기능을 지원함(0.13.0버전 이후).
* 세종 품사 태그 체계 : 2002년도 세종계획 프로젝트의 천만 어절 규모의 말뭉치를 품사 태거의 태그셋 형태로 변형하고 사전으로 구축한 것
- 텍스트 분석 속도가 다른 한국어 형태소 분석기들과 비교하여 빠른 편임. 문장 분리 기능을 비롯한 다양한 편의 기능을 제공함. 라이브러리 차원에서 멀티스레딩을 지원하기 때문에 대량의 텍스트를 분석해야 할 경우, 멀티 코어를 활용하여 빠른 분석이 가능함. 또한 다양한 시스템에서 상황에 맞춰 선택할 수 있도록 소형/중형/대형 모델을 제공함.
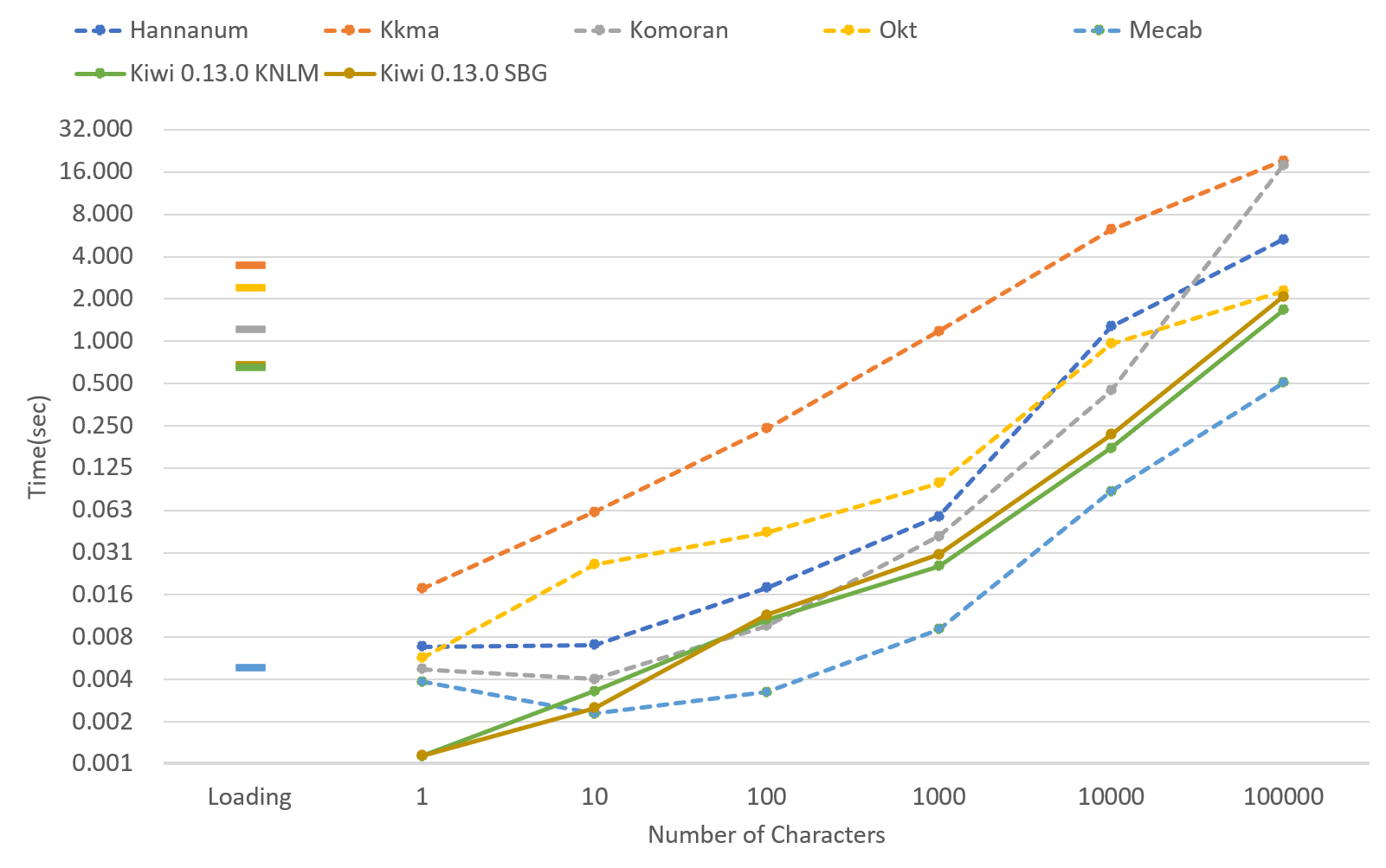
한국어 형태소 분석기별 텍스트 분석 속도
출처 : https://github.com/bab2min/Kiwi
- Kiwi는 미리 한국어 기반의 사전을 정의하여 그 사전을 가지고 형태소를 분석함. 또한, 말뭉치로부터 새로운 단어를 추출하고 새로운 명사에 적합한 결과들만 추려내며, 그 결과를 현재 모델에 자동으로 추가함. 이는 Soynlp이라는 자연어 처리 모델의 장점을 참고한 것으로, 예를 들어 '슈'라는 글자 다음에 어떤 글자가 올지는 예측하기 어렵지만, '슈퍼'라는 글자 다음에는 어떤 글자가 올지, '슈퍼컴'이라는 글자 다음에는 어떤 글자가 올지 예상되는 것처럼 맥락이 하나씩 늘어나면서 다음 글자를 점점 정확하게 예측할 수 있는 점을 참고한 것임.
◎ KOMORAN
- KOMORAN은 KOrean MORphological ANalyzer의 약자로, 2012년부터 형태소 분석기 연구를 시작한 국내기업 Shineware의 기술로만 연구 및 개발된 Java 기반의 한국어 형태소 분석기임. 100% Java로만 개발되었기 때문에 일반 PC, 스마트폰뿐만 아니라 자동차 및 냉장고에서도 JVM만 설치된 환경이라면 어디서든지 사용 가능함.
- Shineware에서 자체 제작한 라이브러리들만을 사용하여 구성되었기 때문에 외부 라이브러리와의 의존성 문제에서 자유로움. 즉, 의존성이 걸린 외부 라이브러리가 업데이트 등으로 변경되었을 때 관련 메소드의 삭제 및 변경으로 인해서 생기는 부담이 전혀 없음.
- 자소 단위 처리, TRIE 사전 등으로 약 32MB 메모리상에서도 동작 가능할 정도로 경량화됨. 라이브러리 적용 후 소스 코드 내 1줄만 추가하여 형태소 분석기를 사용할 준비가 끝나며, 또한 사용자 사전 및 기분석 사전과 같은 외부 자원도 각 파일의 위치만 지정해주면 곧바로 적용이 가능한 정도로 사용법이 쉬움.
- 사용자 사전 및 기분석 사전을 관리하는데 용이한 구조로 설계됨. 사용자 사전 및 기분석 사전은 라인의 가장 앞에 ‘#’ 문자를 넣어서 주석처리가 가능함. 또한, 일반 텍스트 파일의 형태로 되어있어 가독성이 높으며 바로 삽입/삭제/수정이 가능함. 사전을 편집하기 위해서 사전의 구조, 규칙, 포맷 등을 파악할 필요가 없음. 더불어, 편집 후 추가적인 빌드 등과 같은 추가 작업 역시 필요 없음.
- KOMORAN 3.0은 기존 KOMORAN 2.0 대비 속도, 정확도가 개선되었으며 타 형태소 분석기와 달리 여러 어절을 하나의 품사로 분석 가능함으로써 형태소 분석기의 적용 분야에 따라 공백이 포함된 고유명사(영화 제목, 음식점 명, 노래 제목, 전문용어 등)를 더 정확하게 분석할 수 있음. 예를 들어 사용자 사전에 “바람과 함께 사라지다”를 넣거나 별도의 학습 코퍼스로 학습을 시킨 데이터가 있다면 다음과 같은 결과를 출력하게 됨.
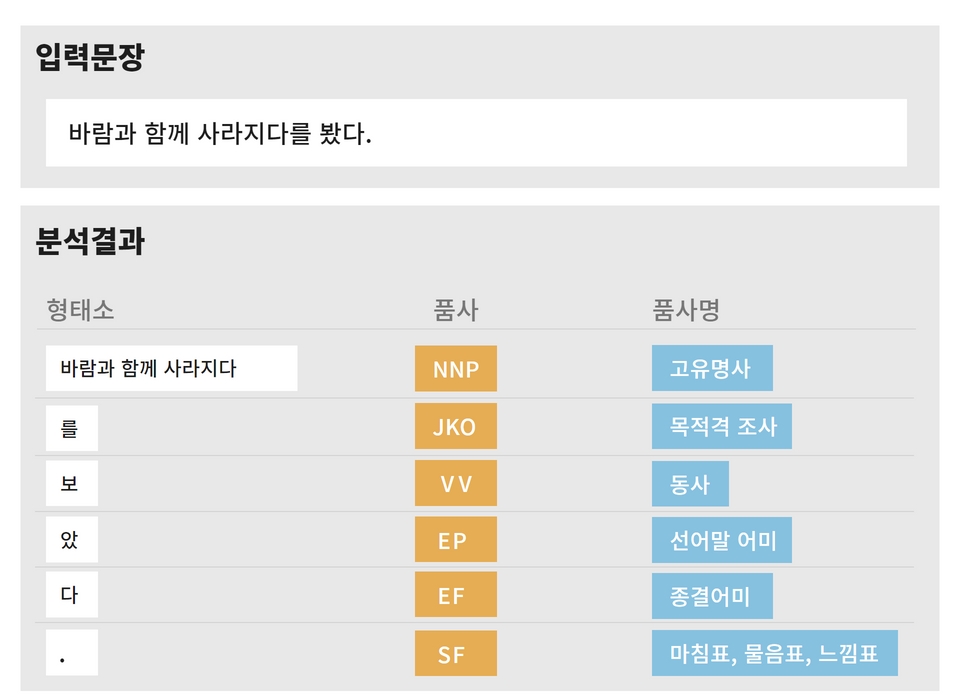
KOMORAN 2.0 형태소 분석기의 분석 결과
출처 : KOMORAN 2.0
- 세종 코퍼스 전체 데이터의 90%를 학습데이터로 사용하고 나머지 10%는 실험데이터로 사용하여 분석 정확률(accuracy)에 대한 실험에서 형태소별 품사 정확률은 95.62%였으며 어절 전체에 포함된 품사를 정확하게 맞춘 경우는 93.37%임. 또한, 한글로만 구성된 어절뿐만 아니라 숫자, 기호, 영어 등을 포함한 전체 어절에 대한 형태소별 품사 정확률 및 어절 정확률은 각각 95.06%, 91.59%였음.
◎ KoBERT
- BERT는 약 33억 개의 단어로 사전훈련 되어있는 기계 번역 모델이지만 구글에서 만든 모델이므로 영어에 대한 정확도가 높고, 한국어에 대해서는 정확도가 떨어짐. 따라서 기존 BERT의 한국어 성능 한계를 극복하기 위해 SKT에서 개발한 한국어 BERT 모델이 KoBERT임.
- KoBERT는 한국어 위키에서 5백만 개의 문장과 5천 4백만 개의 단어로 이루어진 대규모 말뭉치(corpus)를 학습하였으며, 한국어의 불규칙한 언어 변화의 특성을 반영하기 위해 데이터 기반 토큰화 기법을 적용하여 기존 대비 27%의 토큰만으로 2.6% 이상의 성능 향상을 이끌어냈음.
* 토큰화[Tokenization]: 입력된 텍스트를 모델에서 처리할 수 있는 데이터로 변환하는 것
- 대량의 데이터를 빠른 시간에 학습하기 위해 분산 학습 기술을 사용하여, 십억 개 이상의 문장을 다수의 머신에서 빠르게 학습시킴. 더불어, 파이토치(PyTorch), 텐서플로(TensorFlow), ONNX, MXNet을 포함한 다양한 딥러닝 API를 지원함으로써, 많은 분야에서 언어 이해 서비스 확산에 기여하고 있음. 또한, KoBERT는 감정 분석을 긍정과 부정만으로 분류하는 것이 아닌 다중 분류가 가능한 NLP 작업에 강점이 있으며, 한국어 읽기에 특화되어 있으므로 챗봇 및 법적 문서 검토 등 한국어 기반 분석이 요구되는 서비스에 사용됨. 자신의 사용 목적에 따라 파인튜닝이 가능하므로 output layer만을 추가로 달아주면 원하는 결과를 출력해낼 수 있음.
* 파인튜닝 : 사전 학습한 모든 가중치와 더불어 downstream task를 위한 최소한의 가중치를 추가해서 모델을 추가로 학습(미세 조정) 하는 방법
◎ KoGPT-2
- 국내기업 SKT와 아마존웹서비스(AWS)가 협력해 개발한 모델로, 많은 양의 한국어 텍스트에 대해 사전 교육을 받았으며 언어 번역 및 텍스트 생성과 같은 다양한 NLP 작업에 맞게 활용하는 것도 가능함. 한국어로 학습된 오픈소스 기반 GPT-2 모델인 KoGPT-2는 일반적인 질문에 대한 응답 생성, 문장 완성, 챗봇 등 한국어 해석이 요구되는 다양한 애플리케이션의 머신러닝 성능을 향상시킬 수 있음. 한국어 문장을 생성하는데 특화되어 있음.

KoGPT2 기술 적용 챗봇과 기존 인공지능(AI) 챗봇 대화 비교
출처: https://v.daum.net/v/jQlkyGEuBB
□ 맺음말
- 한국어 NLP 오픈소스 프로젝트들의 공통된 특징으로는 사전 훈련된 모델을 제공한다는 점임. KoBERT 및 KoGPT-2와 같은 모델은 감정 분석 등 방대한 양의 데이터에 대해 훈련되어 있음. 이를 통해 연구자와 개발자는 자체 모델을 처음부터 교육할 필요 없이 자연어 처리 애플리케이션을 훨씬 쉽게 만들 수 있음.
- 한국어 자연어 처리는 한국어의 모호성과 어순의 유연성, 접사 사용에 따른 다양한 의미 변화, 의문문과 평서문의 판별이 어려운 점 등의 이유로 영어에 비해 인공지능에 적합한 학습 모델을 제공하는 것이 어렵다고 평가받음. 한국어 자연어 처리 기술 발전의 어려움을 극복하는데 한국어 NLP 오픈소스 프로젝트는 중요한 디딤돌 역할을 하고 있음.
- 자연어 처리에 대한 수요가 다양한 분야에서 증가하고 있으며 시장 규모로는 BFSI(Banking, financial services and insurance) 부문의 성장이 두드러질 전망. 금융이나 보험 분야는 빠르고 넓은 범위에서 자연어 처리 기술과 기법을 도입하고 있음. 고객 유지, 비용 절감, 수익 증가, 규칙과 규정 준수라는 목표 달성에 필요한 정보 검색, 의도 구문 분석, 고객 서비스 및 규정 준수 프로세스 자동화에 자연어 처리가 유용하기 때문임. 사용자의 의도 파악이 필요한 분야에서 자연어 처리 기술이 주목을 받고 있음.
※ 출처
1) https://www.ciokorea.com/tags/21567/NLP/265618
2) https://www.marketsandmarkets.com/Market-Reports/natural-language-processing-nlp-825.html
3) https://www.news1.kr/articles/4916630
4) https://www.bloter.net/newsView/blt202004280010
5) https://www.ajunews.com/view/20210504120317549
6) https://v.daum.net/v/jQlkyGEuBB
7) https://sktelecom.github.io/project/kobert/
8) https://www.shineware.co.kr/products/komoran/
9) https://fastcampus.co.kr/story_article_nlp
10) https://github.com/kakao/khaiii
11) https://github.com/bab2min/Kiwi
12) https://github.com/SKT-AI/KoGPT2
13) https://github.com/SKTBrain/KoBERT
14) https://www.sas.com/ko_kr/insights/analytics/what-is-natural-language-processing-nlp.html
15) https://www.aitimes.kr/news/articleView.html?idxno=15036
16) https://github.com/shineware/KOMORAN
18) https://tech.kakao.com/2018/12/13/khaiii/
22) https://t1.daumcdn.net/cfile/tistory/24582942542946E206?download
23) https://tech.kakaoenterprise.com/117
24) https://www.itworld.co.kr/numbers/82002/265618

| 번호 | 제목 | 작성자 | 조회수 | 작성 |
|---|---|---|---|---|
| 공지 | [2024년] 오픈소스SW 라이선스 가이드 개정판 발간 file | support | 12529 | 2024-01-03 |
| 공지 | [2024년] 기업 오픈소스SW 거버넌스 가이드 개정판 발간 file | support | 10050 | 2024-01-03 |
| 공지 | [2024년] 공공 오픈소스SW 거버넌스 가이드 개정판 발간 file | support | 9947 | 2024-01-03 |
| 공지 | 공개 소프트웨어 연구개발(R&D) 실무 가이드라인 배포 file | support | 22446 | 2022-07-28 |
| 공지 | 공개소프트웨어 연구개발 수행 가이드라인 file | OSS | 20794 | 2018-04-26 |
| 448 | [3월 월간브리핑] 3D 프린팅의 흐름을 바꾼 오픈소스 프로젝트 | support | 7170 | 2023-03-27 |
| 447 | [기획] OpenAI-ChatGPT의 오픈소스 대안 | support | 8468 | 2023-02-20 |
| 446 | [기획기사] 최근 자연어 처리 (NLP) 오픈소스 기술 현황 | support | 8440 | 2023-02-20 |
| 445 | [2월 월간 브리핑] 한국어 자연어 처리(NLP) 오픈소스 프로젝트 | support | 12826 | 2023-02-20 |
| 444 | [기획기사] 실시간 데이터 처리 분석 붐 중심에 선 오픈소스 | support | 3860 | 2023-01-20 |
| 443 | [1월 월간 브리핑] 하둡을 잇는 오픈소스 분석 시장 신흥 강자 기술들 | support | 4102 | 2023-01-20 |
| 442 | [기획] 오픈소스 데이터 시각화 도구 TOP 4 | support | 10501 | 2023-01-20 |
| 441 | [12월 월간브리핑]자율주행 개발을 위한 오픈소스 모형차 플랫폼 현황 | support | 2577 | 2022-12-26 |
| 440 | [기획] 자율주행 오픈소스 데이터셋 TOP 5 소개 | support | 11739 | 2022-12-26 |
| 439 | [기획기사]자율주행기술을 주도하는 오픈소스 프로젝트와 기술 | support | 2420 | 2022-12-26 |
0개 댓글